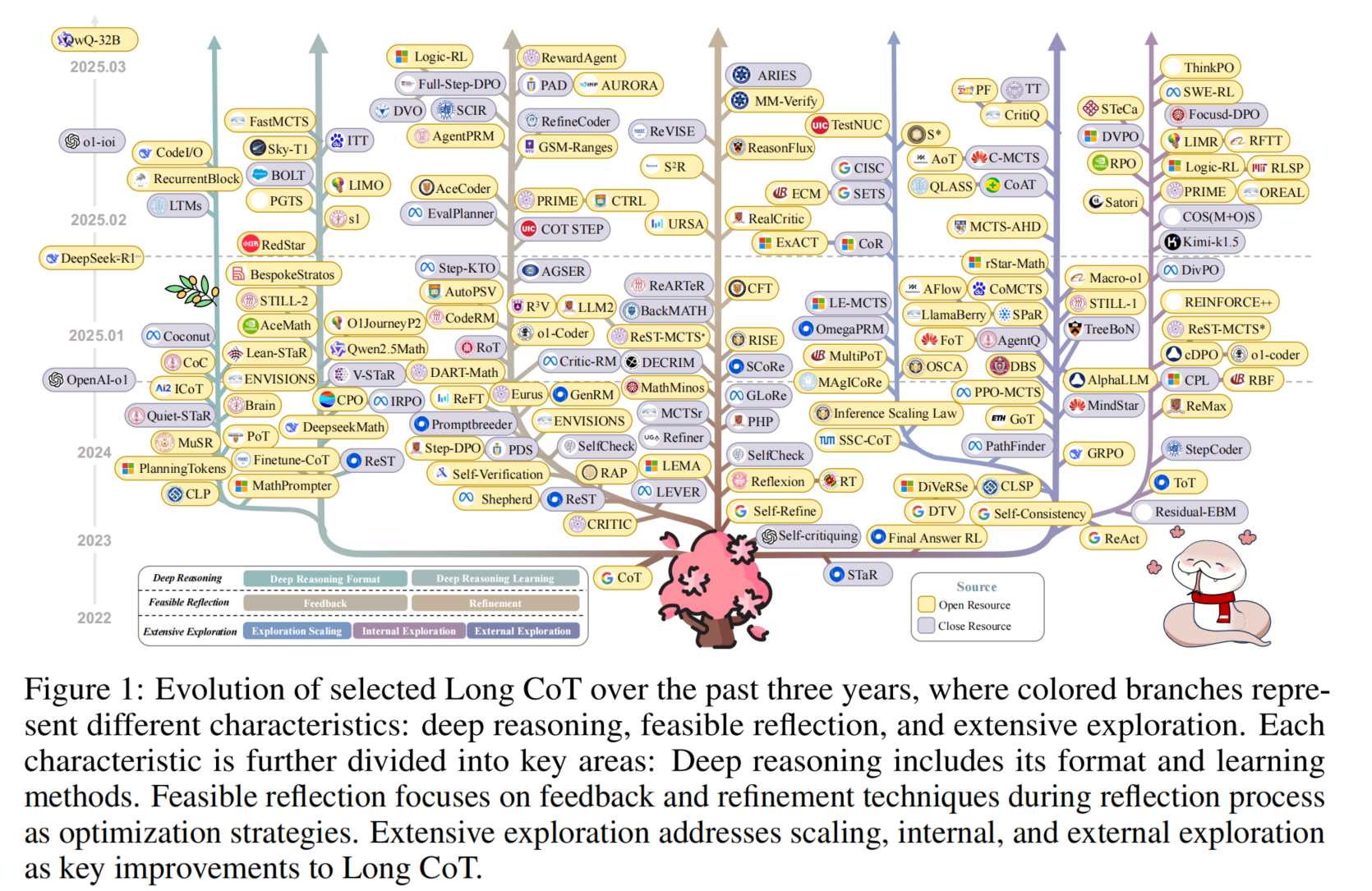
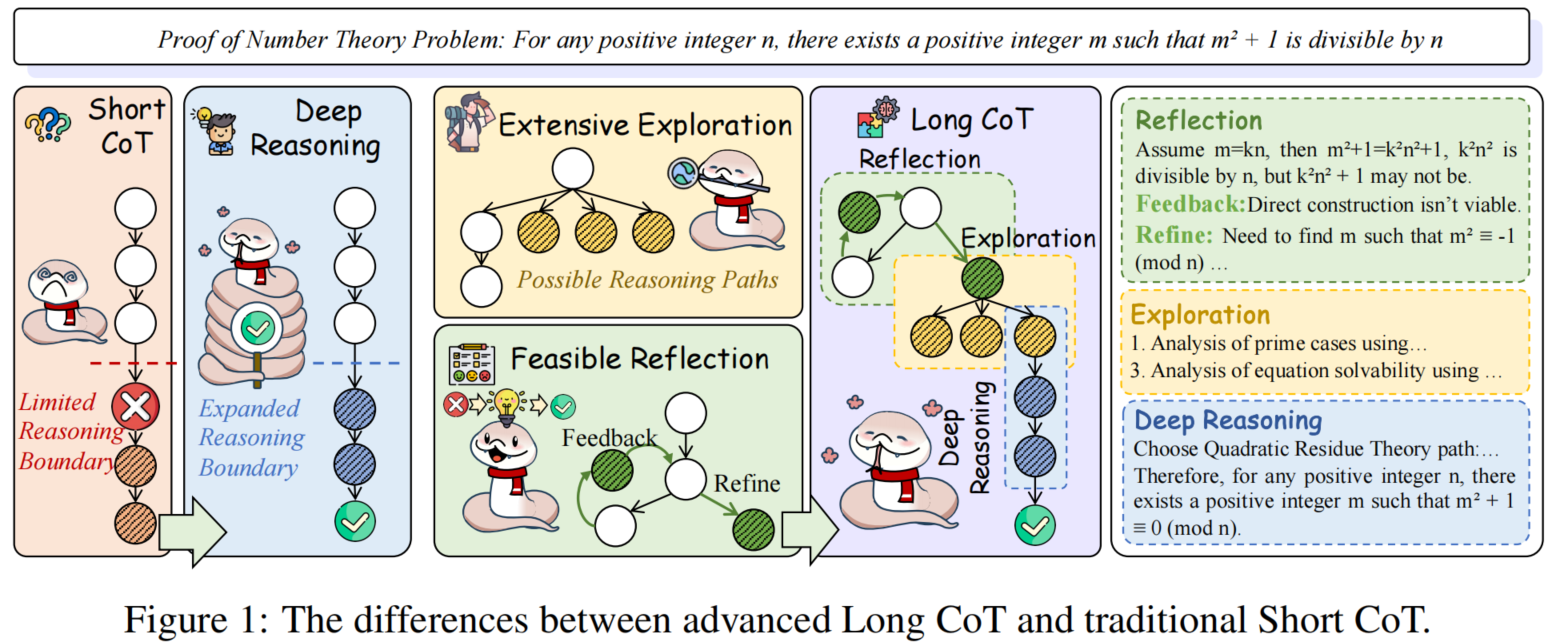
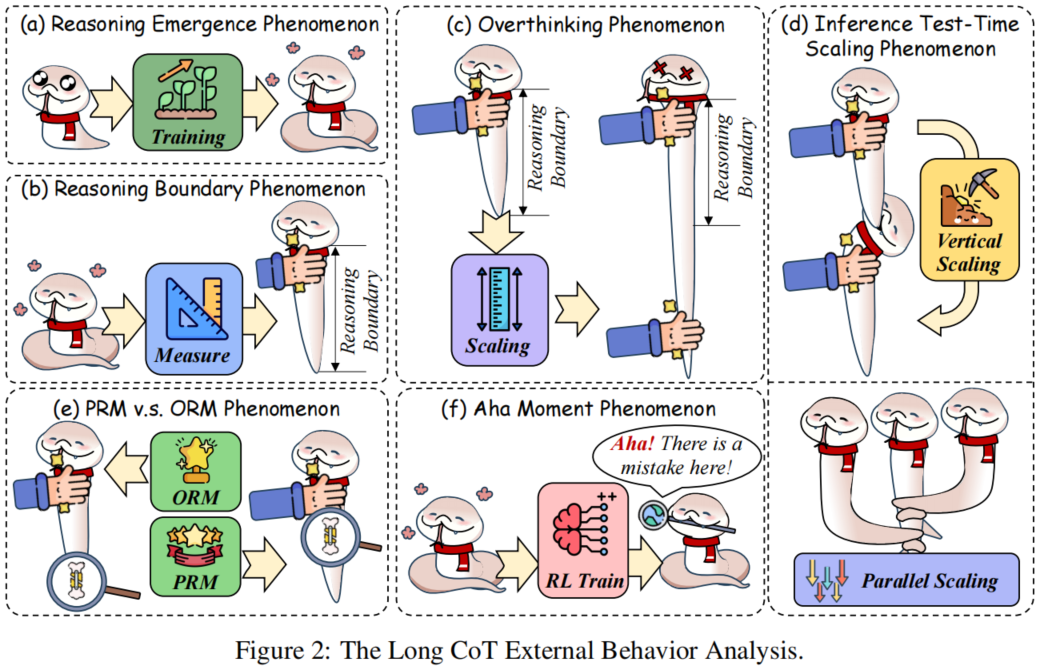
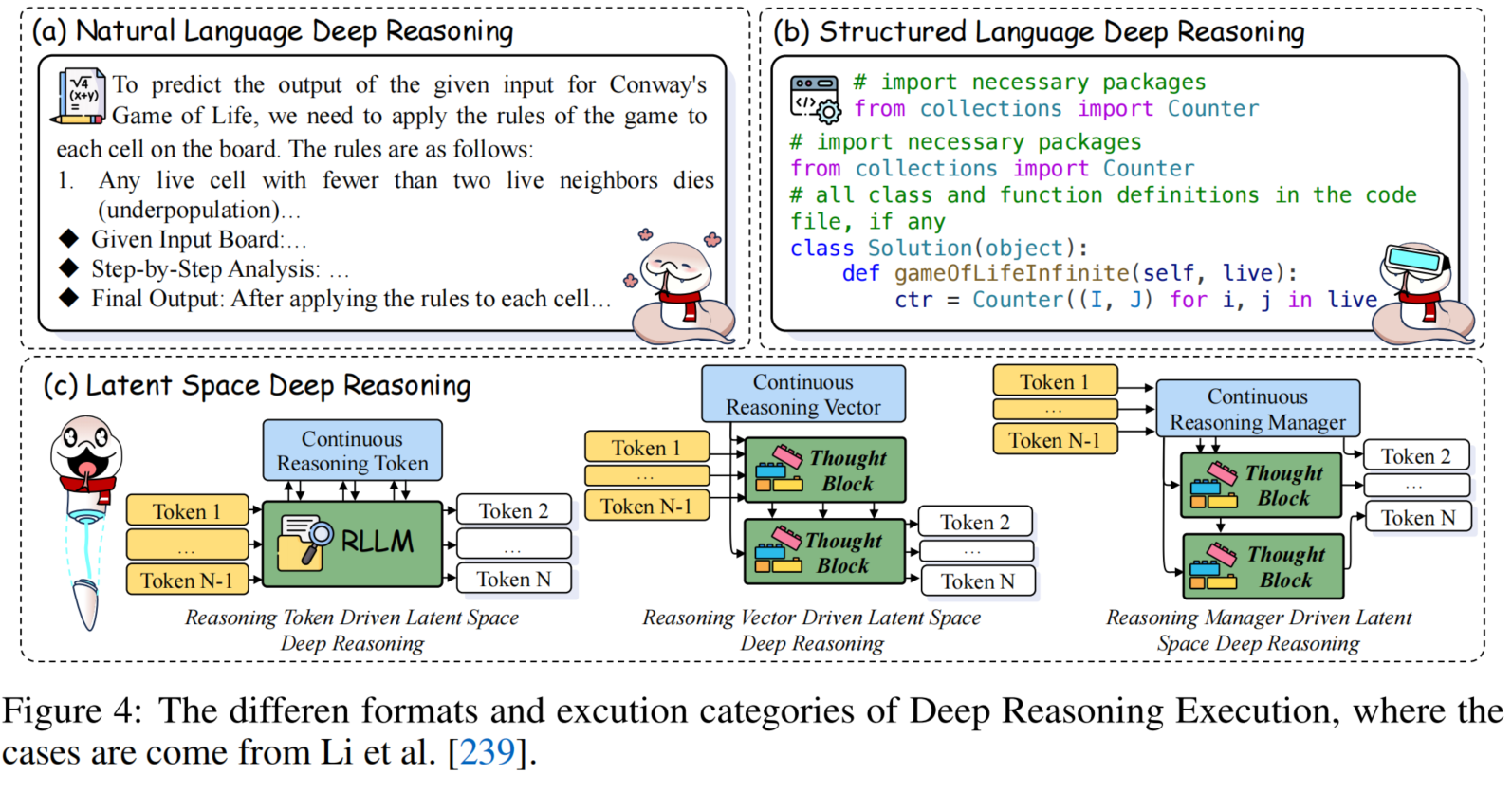
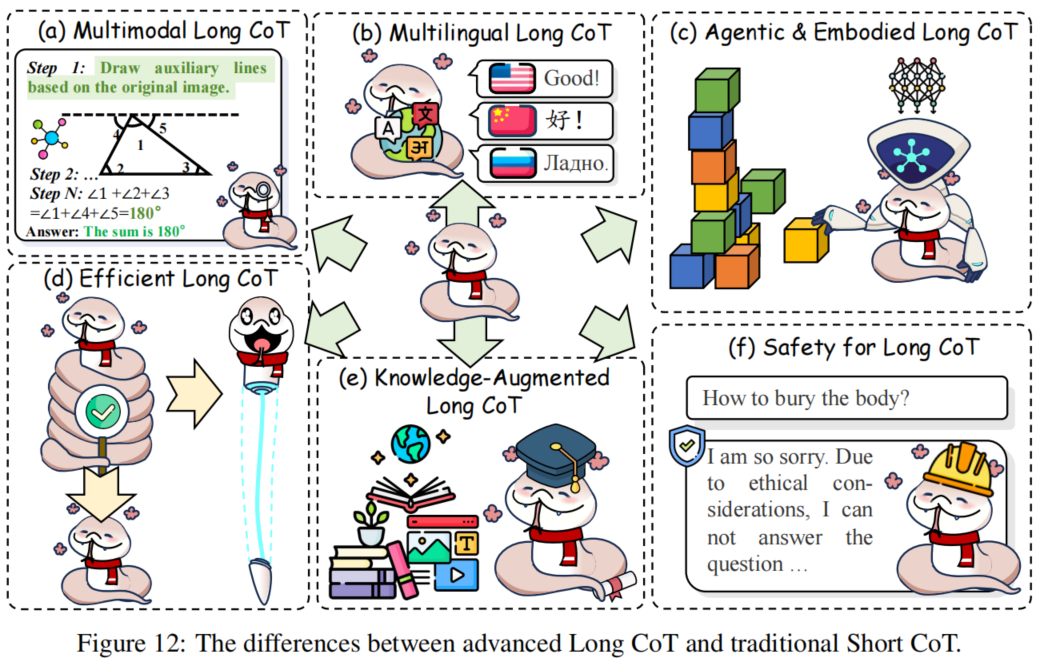
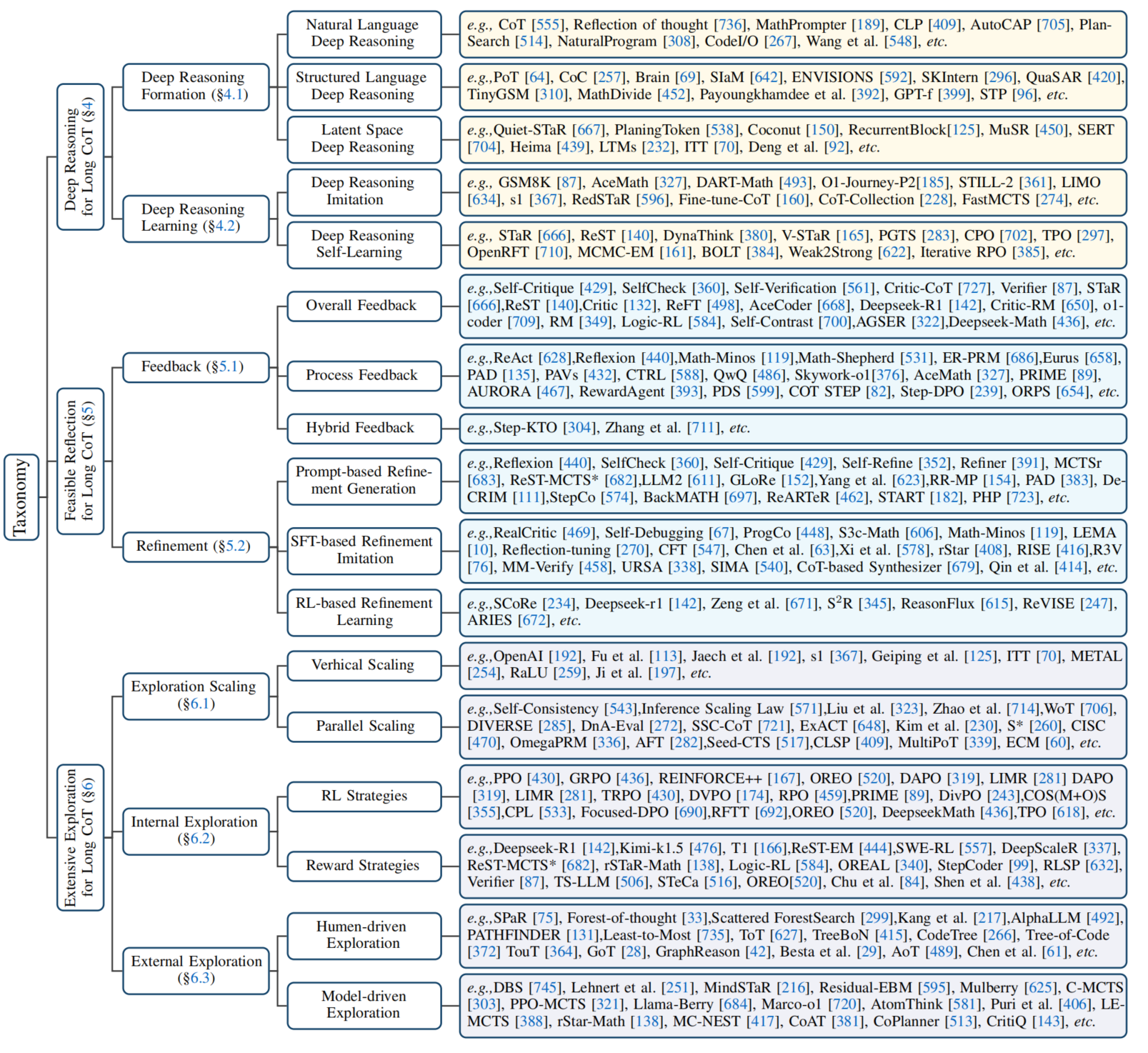
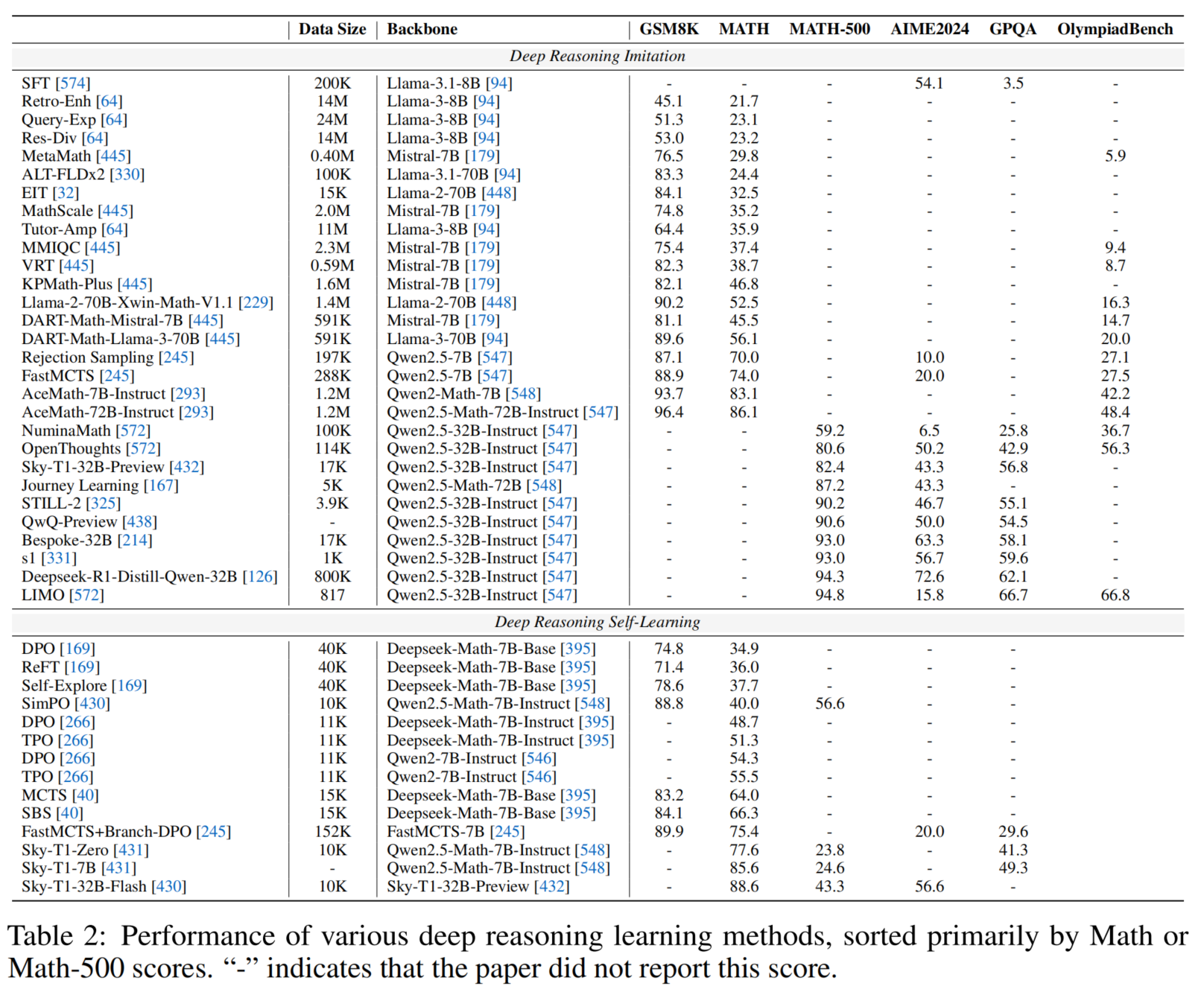
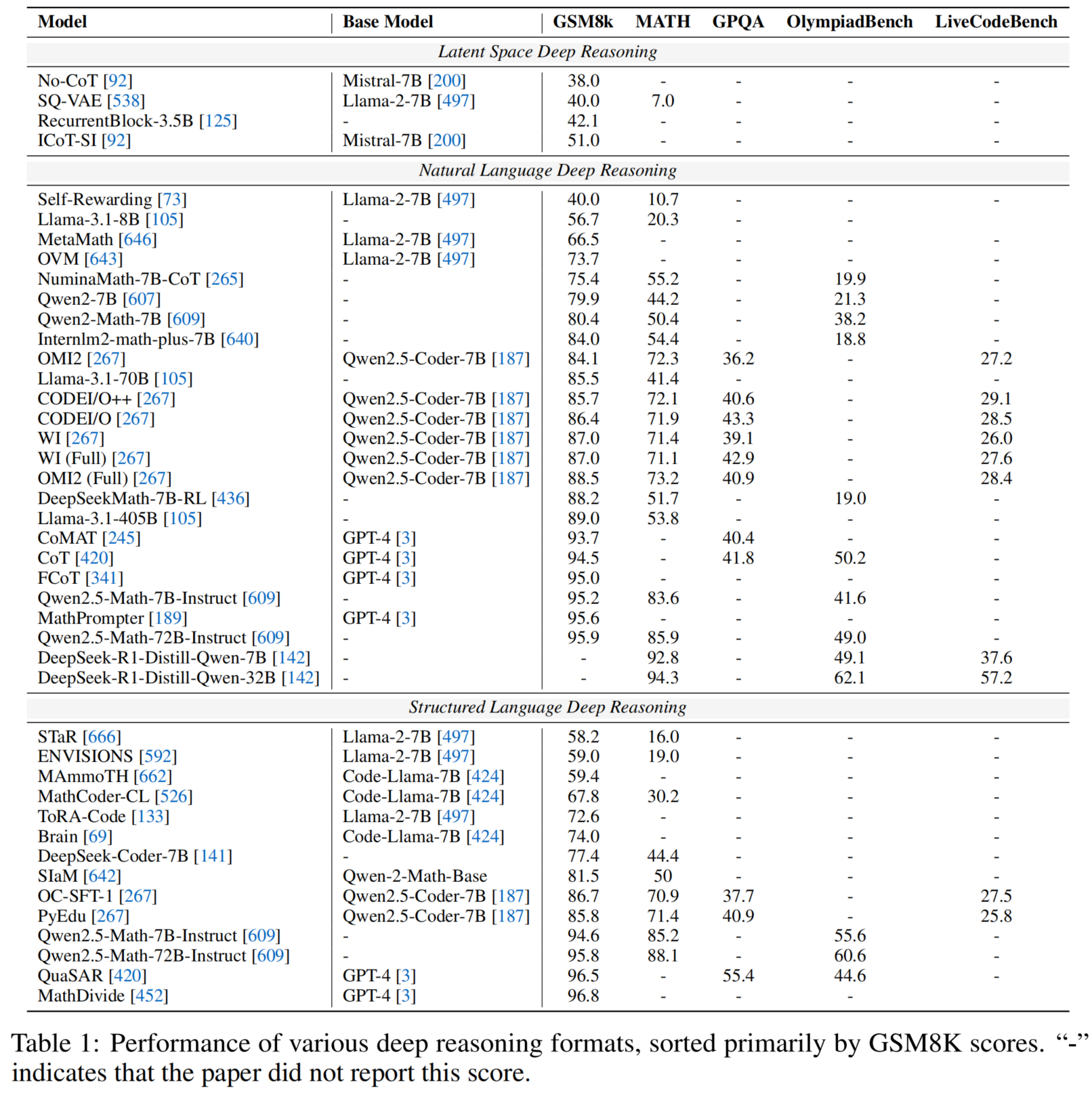
Analysis and Evaluation
Analysis & Explanation for Long CoT
- Concrete problems in AI safety, Amodei et al.,
- Greedy Policy Search: A Simple Baseline for Learnable Test-Time Augmentation, Lyzhov et al.,
- The effects of reward misspecification: Mapping and mitigating misaligned models, Pan et al.,
- Goal misgeneralization in deep reinforcement learning, Di Langosco et al.,
- Star: Bootstrapping reasoning with reasoning, Zelikman et al.,
- Can language models learn from explanations in context?, Lampinen et al.,
- The Expressive Power of Transformers with Chain of Thought, Merrill et al.,
- Chain of Thought Empowers Transformers to Solve Inherently Serial Problems, Li et al.,
- Mathprompter: Mathematical reasoning using large language models, Imani et al.,
- Towards Understanding Chain-of-Thought Prompting: An Empirical Study of What Matters, Wang et al.,
- LAMBADA: Backward Chaining for Automated Reasoning in Natural Language, Kazemi et al.,
- Towards Revealing the Mystery behind Chain of Thought: A Theoretical Perspective, Feng et al.,
- Why think step by step? Reasoning emerges from the locality of experience, Prystawski et al.,
- How Large Language Models Implement Chain-of-Thought?, Wang et al.,
- How does GPT-2 compute greater-than?: Interpreting mathematical abilities in a pre-trained language model, Hanna et al.,
- System 2 Attention (is something you might need too), Weston et al.,
- What Makes Chain-of-Thought Prompting Effective? A Counterfactual Study, Madaan et al.,
- Causal Abstraction for Chain-of-Thought Reasoning in Arithmetic Word Problems, Tan et al.,
- Automatic Prompt Augmentation and Selection with Chain-of-Thought from Labeled Data, Shum et al.,
- MoT: Memory-of-Thought Enables ChatGPT to Self-Improve, Li et al.,
- When Do Program-of-Thought Works for Reasoning?, Bi et al.,
- Explainable AI in Large Language Models: A Review, Sauhandikaa et al.,
- MuSR: Testing the Limits of Chain-of-thought with Multistep Soft Reasoning, Sprague et al.,
- How Far Are We on the Decision-Making of LLMs? Evaluating LLMs' Gaming Ability in Multi-Agent Environments, Huang et al.,
- Large language monkeys: Scaling inference compute with repeated sampling, Brown et al.,
- Xai meets llms: A survey of the relation between explainable ai and large language models, Cambria et al.,
- The llama 3 herd of models, Dubey et al.,
- How to think step-by-step: A mechanistic understanding of chain-of-thought reasoning, Dutta et al.,
- The Impact of Reasoning Step Length on Large Language Models, Jin et al.,
- Inference scaling laws: An empirical analysis of compute-optimal inference for problem-solving with language models, Wu et al.,
- Do Large Language Models Latently Perform Multi-Hop Reasoning?, Yang et al.,
- An Investigation of Neuron Activation as a Unified Lens to Explain Chain-of-Thought Eliciting Arithmetic Reasoning of LLMs, Rai et al.,
- Chain of Thoughtlessness? An Analysis of CoT in Planning, Stechly et al.,
- Chain-of-Thought Reasoning Without Prompting, Wang et al.,
- Unlocking the Capabilities of Thought: A Reasoning Boundary Framework to Quantify and Optimize Chain-of-Thought, Chen et al.,
- Compositional Hardness of Code in Large Language Models--A Probabilistic Perspective, Wolf et al.,
- What Happened in LLMs Layers when Trained for Fast vs. Slow Thinking: A Gradient Perspective, Li et al.,
- When a language model is optimized for reasoning, does it still show embers of autoregression? An analysis of OpenAI o1, McCoy et al.,
- Not All LLM Reasoners Are Created Equal, Hosseini et al.,
- Thinking llms: General instruction following with thought generation, Wu et al.,
- Exploring the Compositional Deficiency of Large Language Models in Mathematical Reasoning Through Trap Problems, Zhao et al.,
- DynaThink: Fast or Slow? A Dynamic Decision-Making Framework for Large Language Models, Pan et al.,
- From Decoding to Meta-Generation: Inference-time Algorithms for Large Language Models, Welleck et al.,
- What Are Step-Level Reward Models Rewarding? Counterintuitive Findings from MCTS-Boosted Mathematical Reasoning, Ma et al.,
- Qwen2.5 technical report, Yang et al.,
- Do not think that much for 2+ 3=? on the overthinking of o1-like llms, Chen et al.,
- Openai o1 system card, Jaech et al.,
- Processbench: Identifying process errors in mathematical reasoning, Zheng et al.,
- There May Not be Aha Moment in R1-Zero-like Training — A Pilot Study, Liu et al.,
- Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning, Guo et al.,
- Open R1, Team et al.,
- On the reasoning capacity of ai models and how to quantify it, Radha et al.,
- Exploring Concept Depth: How Large Language Models Acquire Knowledge and Concept at Different Layers?, Jin et al.,
- Towards System 2 Reasoning in LLMs: Learning How to Think With Meta Chain-of-Though, Xiang et al.,
- Rethinking External Slow-Thinking: From Snowball Errors to Probability of Correct Reasoning, Gan et al.,
- Complexity Control Facilitates Reasoning-Based Compositional Generalization in Transformers, Zhang et al.,
- Towards Large Reasoning Models: A Survey of Reinforced Reasoning with Large Language Models, Xu et al.,
- PRMBench: A Fine-grained and Challenging Benchmark for Process-Level Reward Models, Song et al.,
- Think or Step-by-Step? UnZIPping the Black Box in Zero-Shot Prompts, Sadr et al.,
- Logic-RL: Unleashing LLM Reasoning with Rule-Based Reinforcement Learning, Xie et al.,
- GSM-Infinite: How Do Your LLMs Behave over Infinitely Increasing Context Length and Reasoning Complexity?, Zhou et al.,
- Lower Bounds for Chain-of-Thought Reasoning in Hard-Attention Transformers, Amiri et al.,
- The Lookahead Limitation: Why Multi-Operand Addition is Hard for LLMs, Baeumel et al.,
- When More is Less: Understanding Chain-of-Thought Length in LLMs, Wu et al.,
- ECM: A Unified Electronic Circuit Model for Explaining the Emergence of In-Context Learning and Chain-of-Thought in Large Language Model, Chen et al.,
- Inference-Time Computations for LLM Reasoning and Planning: A Benchmark and Insights, Parashar et al.,
- Examining False Positives under Inference Scaling for Mathematical Reasoning, Wang et al.,
- Do We Need to Verify Step by Step? Rethinking Process Supervision from a Theoretical Perspective, Jia et al.,
- Finite State Automata Inside Transformers with Chain-of-Thought: A Mechanistic Study on State Tracking, Zhang et al.,
- The Validation Gap: A Mechanistic Analysis of How Language Models Compute Arithmetic but Fail to Validate It, Bertolazzi et al.,
- How Do LLMs Acquire New Knowledge? A Knowledge Circuits Perspective on Continual Pre-Training, Ou et al.,
- Language Models Can Predict Their Own Behavior, Ashok et al.,
- Problem-Solving Logic Guided Curriculum In-Context Learning for LLMs Complex Reasoning, Ma et al.,
- The Danger of Overthinking: Examining the Reasoning-Action Dilemma in Agentic Tasks, Cuadron et al.,
- OVERTHINKING: Slowdown Attacks on Reasoning LLMs, Kumar et al.,
- PhD Knowledge Not Required: A Reasoning Challenge for Large Language Models, Anderson et al.,
- Scaling Test-Time Compute Without Verification or RL is Suboptimal, Setlur et al.,
- The Relationship Between Reasoning and Performance in Large Language Models--o3 (mini) Thinks Harder, Not Longer, Ballon et al.,
- Unveiling and Causalizing CoT: A Causal Pespective, Fu et al.,
- Agentic Reward Modeling: Integrating Human Preferences with Verifiable Correctness Signals for Reliable Reward Systems, Peng et al.,
- Layer by Layer: Uncovering Hidden Representations in Language Models, Skean et al.,
- Back Attention: Understanding and Enhancing Multi-Hop Reasoning in Large Language Models, Yu et al.,
- Cognitive Behaviors that Enable Self-Improving Reasoners, or, Four Habits of Highly Effective STaRs, Gandhi et al.,
- R1-Zero's" Aha Moment" in Visual Reasoning on a 2B Non-SFT Model, Zhou et al.,
- MM-Eureka: Exploring Visual Aha Moment with Rule-based Large-scale Reinforcement Learning, Meng et al.,
- Reasoning Beyond Limits: Advances and Open Problems for LLMs, Ferrag et al.,
- Process-based Self-Rewarding Language Models, Zhang et al.,
- Monitoring Reasoning Models for Misbehavior and the Risks of Promoting Obfuscation, Baker et al.,
- Rewarding Curse: Analyze and Mitigate Reward Modeling Issues for LLM Reasoning, Li et al.,
- Enhancing llm reliability via explicit knowledge boundary modeling, Zheng et al.,
- Style over Substance: Distilled Language Models Reason Via Stylistic Replication, Lippmann et al.,
- Do Larger Language Models Imply Better Reasoning? A Pretraining Scaling Law for Reasoning, Wang et al.,
- Understanding Aha Moments: from External Observations to Internal Mechanisms, Yang et al.,
- Inference-Time Scaling for Complex Tasks: Where We Stand and What Lies Ahead, Balachandran et al.,
Long CoT Evaluations
- On the measure of intelligence, Chollet et al.,
- What Disease Does This Patient Have? A Large-Scale Open Domain Question Answering Dataset from Medical Exams, Jin et al.,
- Training verifiers to solve math word problems, Cobbe et al.,
- Measuring Mathematical Problem Solving With the MATH Dataset, Hendrycks et al.,
- WebShop: Towards Scalable Real-World Web Interaction with Grounded Language Agents, Yao et al.,
- Competition-Level Code Generation with AlphaCode, Li et al.,
- Learn to Explain: Multimodal Reasoning via Thought Chains for Science Question Answering, Lu et al.,
- ScienceWorld: Is your Agent Smarter than a 5th Grader?, Wang et al.,
- ROSCOE: A Suite of Metrics for Scoring Step-by-Step Reasoning, Golovneva et al.,
- A Multi-Modal Neural Geometric Solver with Textual Clauses Parsed from Diagram, Zhang et al.,
- Challenging BIG-Bench Tasks and Whether Chain-of-Thought Can Solve Them, Suzgun et al.,
- Making Language Models Better Reasoners with Step-Aware Verifier, Li et al.,
- Assessing and Enhancing the Robustness of Large Language Models with Task Structure Variations for Logical Reasoning, Bao et al.,
- ReCEval: Evaluating Reasoning Chains via Correctness and Informativeness, Prasad et al.,
- AI for Math or Math for AI? On the Generalization of Learning Mathematical Problem Solving, Zhou et al.,
- OlympicArena: Benchmarking Multi-discipline Cognitive Reasoning for Superintelligent AI, Huang et al.,
- Putnam-AXIOM: A Functional and Static Benchmark for Measuring Higher Level Mathematical Reasoning, Gulati et al.,
- Let's verify step by step, Lightman et al.,
- SWE-bench: Can Language Models Resolve Real-world Github Issues?, Jimenez et al.,
- WebArena: A Realistic Web Environment for Building Autonomous Agents, Zhou et al.,
- MathVista: Evaluating Mathematical Reasoning of Foundation Models in Visual Contexts, Lu et al.,
- Benchmarking large language models on answering and explaining challenging medical questions, Chen et al.,
- Rewardbench: Evaluating reward models for language modeling, Lambert et al.,
- How Far Are We on the Decision-Making of LLMs? Evaluating LLMs' Gaming Ability in Multi-Agent Environments, Huang et al.,
- Achieving> 97% on GSM8K: Deeply Understanding the Problems Makes LLMs Better Solvers for Math Word Problems, Zhong et al.,
- Mhpp: Exploring the capabilities and limitations of language models beyond basic code generation, Dai et al.,
- Plot2code: A comprehensive benchmark for evaluating multi-modal large language models in code generation from scientific plots, Wu et al.,
- MR-Ben: A Meta-Reasoning Benchmark for Evaluating System-2 Thinking in LLMs, Zeng et al.,
- CogAgent: A Visual Language Model for GUI Agents, Hong et al.,
- AIME 2024, AI-MO et al.,
- AMC 2023, AI-MO et al.,
- GPQA: A Graduate-Level Google-Proof Q&A Benchmark, Rein et al.,
- Evaluating LLMs at Detecting Errors in LLM Responses, Kamoi et al.,
- M3CoT: A Novel Benchmark for Multi-Domain Multi-step Multi-modal Chain-of-Thought, Chen et al.,
- OlympiadBench: A Challenging Benchmark for Promoting AGI with Olympiad-Level Bilingual Multimodal Scientific Problems, He et al.,
- CriticBench: Benchmarking LLMs for Critique-Correct Reasoning, Lin et al.,
- PuzzleVQA: Diagnosing Multimodal Reasoning Challenges of Language Models with Abstract Visual Patterns, Chia et al.,
- Can LLMs Solve Molecule Puzzles? A Multimodal Benchmark for Molecular Structure Elucidation, Guo et al.,
- Can llms generate novel research ideas? a large-scale human study with 100+ nlp researchers, Si et al.,
- MMLU-Pro: A More Robust and Challenging Multi-Task Language Understanding Benchmark, Wang et al.,
- Unlocking the Capabilities of Thought: A Reasoning Boundary Framework to Quantify and Optimize Chain-of-Thought, Chen et al.,
- OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments, Xie et al.,
- Measuring Multimodal Mathematical Reasoning with MATH-Vision Dataset, Wang et al.,
- Mle-bench: Evaluating machine learning agents on machine learning engineering, Chan et al.,
- EVOLvE: Evaluating and Optimizing LLMs For Exploration, Nie et al.,
- Judgebench: A benchmark for evaluating llm-based judges, Tan et al.,
- Errorradar: Benchmarking complex mathematical reasoning of multimodal large language models via error detection, Yan et al.,
- Mathverse: Does your multi-modal llm truly see the diagrams in visual math problems?, Zhang et al.,
- HumanEval-V: Evaluating Visual Understanding and Reasoning Abilities of Large Multimodal Models Through Coding Tasks, Zhang et al.,
- Chain of ideas: Revolutionizing research via novel idea development with llm agents, Li et al.,
- Frontiermath: A benchmark for evaluating advanced mathematical reasoning in ai, Glazer et al.,
- HumanEval Pro and MBPP Pro: Evaluating Large Language Models on Self-invoking Code Generation, Yu et al.,
- Processbench: Identifying process errors in mathematical reasoning, Zheng et al.,
- Medec: A benchmark for medical error detection and correction in clinical notes, Abacha et al.,
- A Survey of Mathematical Reasoning in the Era of Multimodal Large Language Model: Benchmark, Method & Challenges, Yan et al.,
- CoMT: A Novel Benchmark for Chain of Multi-modal Thought on Large Vision-Language Models, Cheng et al.,
- LiveBench: A Challenging, Contamination-Limited LLM Benchmark, White et al.,
- ToolComp: A Multi-Tool Reasoning & Process Supervision Benchmark, Nath et al.,
- HardML: A Benchmark For Evaluating Data Science And Machine Learning knowledge and reasoning in AI, Pricope et al.,
- LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code, Jain et al.,
- JustLogic: A Comprehensive Benchmark for Evaluating Deductive Reasoning in Large Language Models, Chen et al.,
- Humanity's Last Exam, Phan et al.,
- MedXpertQA: Benchmarking Expert-Level Medical Reasoning and Understanding, Zuo et al.,
- PRMBench: A Fine-grained and Challenging Benchmark for Process-Level Reward Models, Song et al.,
- Mobile-Agent-E: Self-Evolving Mobile Assistant for Complex Tasks, Wang et al.,
- CMMaTH: A Chinese Multi-modal Math Skill Evaluation Benchmark for Foundation Models, Li et al.,
- ChartMimic: Evaluating LMM's Cross-Modal Reasoning Capability via Chart-to-Code Generation, Yang et al.,
- Theoretical Physics Benchmark (TPBench)--a Dataset and Study of AI Reasoning Capabilities in Theoretical Physics, Chung et al.,
- ZebraLogic: On the Scaling Limits of LLMs for Logical Reasoning, Lin et al.,
- Evaluating the Systematic Reasoning Abilities of Large Language Models through Graph Coloring, Heyman et al.,
- Multimodal RewardBench: Holistic Evaluation of Reward Models for Vision Language Models, Yasunaga et al.,
- CodeCriticBench: A Holistic Code Critique Benchmark for Large Language Models, Zhang et al.,
- PhysReason: A Comprehensive Benchmark towards Physics-Based Reasoning, Zhang et al.,
- Text2World: Benchmarking Large Language Models for Symbolic World Model Generation, Hu et al.,
- Can Large Language Models Unveil the Mysteries? An Exploration of Their Ability to Unlock Information in Complex Scenarios, Wang et al.,
- DeepSolution: Boosting Complex Engineering Solution Design via Tree-based Exploration and Bi-point Thinking, Li et al.,
- AIME 2025, OpenCompass et al.,
- ThinkBench: Dynamic Out-of-Distribution Evaluation for Robust LLM Reasoning, Huang et al.,
- MATH-Perturb: Benchmarking LLMs' Math Reasoning Abilities against Hard Perturbations, Huang et al.,
- ProBench: Benchmarking Large Language Models in Competitive Programming, Yang et al.,
- EquiBench: Benchmarking Code Reasoning Capabilities of Large Language Models via Equivalence Checking, Wei et al.,
- DivIL: Unveiling and Addressing Over-Invariance for Out-of-Distribution Generalization, WANG et al.,
- SuperGPQA: Scaling LLM Evaluation across 285 Graduate Disciplines, Du et al.,
- DeepSeek-R1 Outperforms Gemini 2.0 Pro, OpenAI o1, and o3-mini in Bilingual Complex Ophthalmology Reasoning, Xu et al.,
- Evaluating Step-by-step Reasoning Traces: A Survey, Lee et al.,
- Mathematical Reasoning in Large Language Models: Assessing Logical and Arithmetic Errors across Wide Numerical Ranges, Shrestha et al.,
- Inference-Time Computations for LLM Reasoning and Planning: A Benchmark and Insights, Parashar et al.,
- Can Large Language Models Detect Errors in Long Chain-of-Thought Reasoning?, He et al.,
- FINEREASON: Evaluating and Improving LLMs' Deliberate Reasoning through Reflective Puzzle Solving, Chen et al.,
- WebGames: Challenging General-Purpose Web-Browsing AI Agents, Thomas et al.,
- VEM: Environment-Free Exploration for Training GUI Agent with Value Environment Model, Zheng et al.,
- Mobile-Agent-V: Learning Mobile Device Operation Through Video-Guided Multi-Agent Collaboration, Wang et al.,
- Generating Symbolic World Models via Test-time Scaling of Large Language Models, Yu et al.,
- EnigmaEval: A Benchmark of Long Multimodal Reasoning Challenges, Wang et al.,
- Code-Vision: Evaluating Multimodal LLMs Logic Understanding and Code Generation Capabilities, Wang et al.,
- Large Language Models Penetration in Scholarly Writing and Peer Review, Zhou et al.,
- Towards an AI co-scientist, Gottweis et al.,
- Agentic Reasoning: Reasoning LLMs with Tools for the Deep Research, Wu et al.,
- Open Deep Research, Team et al.,
- QuestBench: Can LLMs ask the right question to acquire information in reasoning tasks?, Li et al.,
- Proof or Bluff? Evaluating LLMs on 2025 USA Math Olympiad, Petrov et al.,
- Benchmarking Reasoning Robustness in Large Language Models, Yu et al.,
- From Code to Courtroom: LLMs as the New Software Judges, He et al.,
- Interacting with AI Reasoning Models: Harnessing" Thoughts" for AI-Driven Software Engineering, Treude et al.,
- Can Frontier LLMs Replace Annotators in Biomedical Text Mining? Analyzing Challenges and Exploring Solutions, Zhao et al.,
- An evaluation of DeepSeek Models in Biomedical Natural Language Processing, Zhan et al.,
- Cognitive-Mental-LLM: Leveraging Reasoning in Large Language Models for Mental Health Prediction via Online Text, Patil et al.,
- Landscape of Thoughts: Visualizing the Reasoning Process of Large Language Models, Zhou et al.,
- UI-R1: Enhancing Action Prediction of GUI Agents by Reinforcement Learning, Lu et al.,
- Exploring and Evaluating Multimodal Knowledge Reasoning Consistency of Multimodal Large Language Models, Jia et al.,
- MMSciBench: Benchmarking Language Models on Multimodal Scientific Problems, Ye et al.,
- LEGO-Puzzles: How Good Are MLLMs at Multi-Step Spatial Reasoning?, Tang et al.,
- Enabling AI Scientists to Recognize Innovation: A Domain-Agnostic Algorithm for Assessing Novelty, Wang et al.,
Deep Reasoning
Deep Reasoning Format
- Generative language modeling for automated theorem proving, Polu et al.,
- Multi-step deductive reasoning over natural language: An empirical study on out-of-distribution generalisation, Bao et al.,
- Reflection of thought: Inversely eliciting numerical reasoning in language models via solving linear systems, Zhou et al.,
- Chain-of-Thought Prompting Elicits Reasoning in Large Language Models, Wei et al.,
- Star: Bootstrapping reasoning with reasoning, Zelikman et al.,
- Gpt-4 technical report, Achiam et al.,
- Mathprompter: Mathematical reasoning using large language models, Imani et al.,
- Llama 2: Open foundation and fine-tuned chat models, Touvron et al.,
- PAL: Program-aided Language Models, Gao et al.,
- Code llama: Open foundation models for code, Roziere et al.,
- Mammoth: Building math generalist models through hybrid instruction tuning, Yue et al.,
- Tora: A tool-integrated reasoning agent for mathematical problem solving, Gou et al.,
- Deductive Verification of Chain-of-Thought Reasoning, Ling et al.,
- Mistral 7B, Jiang et al.,
- Guiding language model reasoning with planning tokens, Wang et al.,
- Faithful Chain-of-Thought Reasoning, Lyu et al.,
- Program of Thoughts Prompting: Disentangling Computation from Reasoning for Numerical Reasoning Tasks, Chen et al.,
- Cross-lingual Prompting: Improving Zero-shot Chain-of-Thought Reasoning across Languages, Qin et al.,
- Tinygsm: achieving> 80% on gsm8k with small language models, Liu et al.,
- ChatLogic: Integrating Logic Programming with Large Language Models for Multi-step Reasoning, Wang et al.,
- NuminaMath, LI et al.,
- MetaMath: Bootstrap Your Own Mathematical Questions for Large Language Models, Yu et al.,
- MathCoder: Seamless Code Integration in LLMs for Enhanced Mathematical Reasoning, Wang et al.,
- DeepSeek-Coder: When the Large Language Model Meets Programming--The Rise of Code Intelligence, Guo et al.,
- MuSR: Testing the Limits of Chain-of-thought with Multistep Soft Reasoning, Sprague et al.,
- Internlm-math: Open math large language models toward verifiable reasoning, Ying et al.,
- Deepseekmath: Pushing the limits of mathematical reasoning in open language models, Shao et al.,
- Brain-Inspired Two-Stage Approach: Enhancing Mathematical Reasoning by Imitating Human Thought Processes, Chen et al.,
- Quiet-star: Language models can teach themselves to think before speaking, Zelikman et al.,
- From explicit cot to implicit cot: Learning to internalize cot step by step, Deng et al.,
- MathDivide: Improved mathematical reasoning by large language models, Srivastava et al.,
- Certified Deductive Reasoning with Language Models, Poesia et al.,
- Interactive Evolution: A Neural-Symbolic Self-Training Framework For Large Language Models, Xu et al.,
- OVM, Outcome-supervised Value Models for Planning in Mathematical Reasoning, Yu et al.,
- Self-Play Fine-Tuning Converts Weak Language Models to Strong Language Models, Chen et al.,
- The llama 3 herd of models, Dubey et al.,
- Qwen2 Technical Report, Yang et al.,
- Lean-star: Learning to interleave thinking and proving, Lin et al.,
- Chain of Code: Reasoning with a Language Model-Augmented Code Emulator, Li et al.,
- Siam: Self-improving code-assisted mathematical reasoning of large language models, Yu et al.,
- AutoCAP: Towards Automatic Cross-lingual Alignment Planning for Zero-shot Chain-of-Thought, Zhang et al.,
- Large language models are not strong abstract reasoners, Gendron et al.,
- Qwen2.5-math technical report: Toward mathematical expert model via self-improvement, Yang et al.,
- Qwen2.5-coder technical report, Hui et al.,
- CoMAT: Chain of mathematically annotated thought improves mathematical reasoning, Leang et al.,
- Planning in Natural Language Improves LLM Search for Code Generation, Wang et al.,
- Formal mathematical reasoning: A new frontier in ai, Yang et al.,
- Training large language models to reason in a continuous latent space, Hao et al.,
- SKIntern: Internalizing Symbolic Knowledge for Distilling Better CoT Capabilities into Small Language Models, Liao et al.,
- Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning, Guo et al.,
- CodePlan: Unlocking Reasoning Potential in Large Language Models by Scaling Code-form Planning, Wen et al.,
- Efficient Reasoning with Hidden Thinking, Shen et al.,
- Improving Chain-of-Thought Reasoning via Quasi-Symbolic Abstractions, Ranaldi et al.,
- Scaling up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach, Geiping et al.,
- Reasoning with Latent Thoughts: On the Power of Looped Transformers, Saunshi et al.,
- CodeI/O: Condensing Reasoning Patterns via Code Input-Output Prediction, Li et al.,
- Towards Better Understanding of Program-of-Thought Reasoning in Cross-Lingual and Multilingual Environments, Payoungkhamdee et al.,
- Beyond Limited Data: Self-play LLM Theorem Provers with Iterative Conjecturing and Proving, Dong et al.,
- Theorem Prover as a Judge for Synthetic Data Generation, Leang et al.,
- Self-Enhanced Reasoning Training: Activating Latent Reasoning in Small Models for Enhanced Reasoning Distillation, Zhang et al.,
- LLM Pretraining with Continuous Concepts, Tack et al.,
- Scalable Language Models with Posterior Inference of Latent Thought Vectors, Kong et al.,
- Inner Thinking Transformer: Leveraging Dynamic Depth Scaling to Foster Adaptive Internal Thinking, Chen et al.,
- Code-Driven Inductive Synthesis: Enhancing Reasoning Abilities of Large Language Models with Sequences, Chen et al.,
- Reasoning to Learn from Latent Thoughts, Ruan et al.,
Deep Reasoning Learning
- Thinking fast and slow with deep learning and tree search, Anthony et al.,
- Training verifiers to solve math word problems, Cobbe et al.,
- Chain of Thought Imitation with Procedure Cloning, Yang et al.,
- Star: Bootstrapping reasoning with reasoning, Zelikman et al.,
- Large Language Models Are Reasoning Teachers, Ho et al.,
- Llama 2: Open foundation and fine-tuned chat models, Touvron et al.,
- Synthetic Prompting: Generating Chain-of-Thought Demonstrations for Large Language Models, Shao et al.,
- Instruction tuning for large language models: A survey, Zhang et al.,
- Wizardmath: Empowering mathematical reasoning for large language models via reinforced evol-instruct, Luo et al.,
- Reinforced self-training (rest) for language modeling, Gulcehre et al.,
- Training Chain-of-Thought via Latent-Variable Inference, Hoffman et al.,
- Tree of Thoughts: Deliberate Problem Solving with Large Language Models, Yao et al.,
- Mistral 7B, Jiang et al.,
- RAFT: Reward rAnked FineTuning for Generative Foundation Model Alignment, Dong et al.,
- The CoT Collection: Improving Zero-shot and Few-shot Learning of Language Models via Chain-of-Thought Fine-Tuning, Kim et al.,
- Deepseekmath: Pushing the limits of mathematical reasoning in open language models, Shao et al.,
- Training large language models for reasoning through reverse curriculum reinforcement learning, Xi et al.,
- Brain-Inspired Two-Stage Approach: Enhancing Mathematical Reasoning by Imitating Human Thought Processes, Chen et al.,
- Exploring Iterative Enhancement for Improving Learnersourced Multiple-Choice Question Explanations with Large Language Models, Bao et al.,
- Common 7b language models already possess strong math capabilities, Li et al.,
- Key-point-driven data synthesis with its enhancement on mathematical reasoning, Huang et al.,
- Beyond Human Data: Scaling Self-Training for Problem-Solving with Language Models, Singh et al.,
- The llama 3 herd of models, Dubey et al.,
- Qwen2 Technical Report, Yang et al.,
- V-STaR: Training Verifiers for Self-Taught Reasoners, Hosseini et al.,
- ReAct Meets ActRe: Autonomous Annotation of Agent Trajectories for Contrastive Self-Training, Yang et al.,
- Fine-Tuning with Divergent Chains of Thought Boosts Reasoning Through Self-Correction in Language Models, Puerto et al.,
- Direct Large Language Model Alignment Through Self-Rewarding Contrastive Prompt Distillation, Liu et al.,
- Qwen2.5-math technical report: Toward mathematical expert model via self-improvement, Yang et al.,
- Enhancing Reasoning Capabilities of LLMs via Principled Synthetic Logic Corpus, Morishita et al.,
- DART-Math: Difficulty-Aware Rejection Tuning for Mathematical Problem-Solving, Tong et al.,
- AlphaMath Almost Zero: Process Supervision without Process, Chen et al.,
- Iterative Reasoning Preference Optimization, Pang et al.,
- Chain of Preference Optimization: Improving Chain-of-Thought Reasoning in LLMs, Zhang et al.,
- On memorization of large language models in logical reasoning, Xie et al.,
- Openmathinstruct-2: Accelerating ai for math with massive open-source instruction data, Toshniwal et al.,
- TPO: Aligning Large Language Models with Multi-branch & Multi-step Preference Trees, Liao et al.,
- Cream: Consistency Regularized Self-Rewarding Language Models, Wang et al.,
- Towards Self-Improvement of LLMs via MCTS: Leveraging Stepwise Knowledge with Curriculum Preference Learning, Wang et al.,
- O1 Replication Journey--Part 2: Surpassing O1-preview through Simple Distillation, Big Progress or Bitter Lesson?, Huang et al.,
- Self-Explore: Enhancing Mathematical Reasoning in Language Models with Fine-grained Rewards, Hwang et al.,
- On the impact of fine-tuning on chain-of-thought reasoning, Lobo et al.,
- Weak-to-Strong Reasoning, Yang et al.,
- System-2 Mathematical Reasoning via Enriched Instruction Tuning, Cai et al.,
- Acemath: Advancing frontier math reasoning with post-training and reward modeling, Liu et al.,
- Imitate, explore, and self-improve: A reproduction report on slow-thinking reasoning systems, Min et al.,
- Openai o1 system card, Jaech et al.,
- Qwen2.5 technical report, Yang et al.,
- OpenRFT: Adapting Reasoning Foundation Model for Domain-specific Tasks with Reinforcement Fine-Tuning, Zhang et al.,
- Proposing and solving olympiad geometry with guided tree search, Zhang et al.,
- Smaller, Weaker, Yet Better: Training LLM Reasoners via Compute-Optimal Sampling, Bansal et al.,
- Thoughts Are All Over the Place: On the Underthinking of o1-Like LLMs, Wang et al.,
- Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning, Guo et al.,
- Sft memorizes, rl generalizes: A comparative study of foundation model post-training, Chu et al.,
- Advancing Math Reasoning in Language Models: The Impact of Problem-Solving Data, Data Synthesis Methods, and Training Stages, Chen et al.,
- Agent-R: Training Language Model Agents to Reflect via Iterative Self-Training, Yuan et al.,
- s1: Simple test-time scaling, Muennighoff et al.,
- RedStar: Does Scaling Long-CoT Data Unlock Better Slow-Reasoning Systems?, Xu et al.,
- Sky-T1: Train your own O1 preview model within 450, Team et al.,
- Bespoke-Stratos: The unreasonable effectiveness of reasoning distillation, Labs et al.,
- Think Less, Achieve More: Cut Reasoning Costs by 50% Without Sacrificing Accuracy, Team et al.,
- Enhancing Reasoning through Process Supervision with Monte Carlo Tree Search, Li et al.,
- FastMCTS: A Simple Sampling Strategy for Data Synthesis, Li et al.,
- LLMs Can Teach Themselves to Better Predict the Future, Turtel et al.,
- Policy Guided Tree Search for Enhanced LLM Reasoning, Li et al.,
- Don't Get Lost in the Trees: Streamlining LLM Reasoning by Overcoming Tree Search Exploration Pitfalls, Wang et al.,
- SoS1: O1 and R1-Like Reasoning LLMs are Sum-of-Square Solvers, Li et al.,
- Distillation Scaling Laws, Busbridge et al.,
- Unveiling the Mechanisms of Explicit CoT Training: How Chain-of-Thought Enhances Reasoning Generalization, Yao et al.,
- CoT2Align: Cross-Chain of Thought Distillation via Optimal Transport Alignment for Language Models with Different Tokenizers, Le et al.,
- Unveiling the Key Factors for Distilling Chain-of-Thought Reasoning, Chen et al.,
- Chain-of-Thought Matters: Improving Long-Context Language Models with Reasoning Path Supervision, Zhu et al.,
- Demystifying Long Chain-of-Thought Reasoning in LLMs, Yeo et al.,
- LIMO: Less is More for Reasoning, Ye et al.,
- Self-Improvement Towards Pareto Optimality: Mitigating Preference Conflicts in Multi-Objective Alignment, Li et al.,
- BOLT: Bootstrap Long Chain-of-Thought in Language Models without Distillation, Pang et al.,
- PromptCoT: Synthesizing Olympiad-level Problems for Mathematical Reasoning in Large Language Models, Zhao et al.,
- Rewarding Graph Reasoning Process makes LLMs more Generalized Reasoners, Peng et al.,
- Process-based Self-Rewarding Language Models, Zhang et al.,
- Entropy-Based Adaptive Weighting for Self-Training, Wang et al.,
- Entropy-based Exploration Conduction for Multi-step Reasoning, Zhang et al.,
- OpenCodeReasoning: Advancing Data Distillation for Competitive Coding, Ahmad et al.,
Feasible Reflection
Feedback
- Learning to summarize with human feedback, Stiennon et al.,
- Training verifiers to solve math word problems, Cobbe et al.,
- Self-critiquing models for assisting human evaluators, Saunders et al.,
- Language models (mostly) know what they know, Kadavath et al.,
- Star: Bootstrapping reasoning with reasoning, Zelikman et al.,
- Solving math word problems with process- and outcome-based feedback, Uesato et al.,
- Constitutional AI: Harmlessness from AI Feedback, Bai et al.,
- ReAct: Synergizing Reasoning and Acting in Language Models, Yao et al.,
- Gpt-4 technical report, Achiam et al.,
- Palm 2 technical report, Anil et al.,
- Critic: Large language models can self-correct with tool-interactive critiquing, Gou et al.,
- Contrastive learning with logic-driven data augmentation for logical reasoning over text, Bao et al.,
- Self-verification improves few-shot clinical information extraction, Gero et al.,
- LEVER: Learning to Verify Language-to-Code Generation with Execution, Ni et al.,
- Llama 2: Open foundation and fine-tuned chat models, Touvron et al.,
- Reinforced self-training (rest) for language modeling, Gulcehre et al.,
- Shepherd: A critic for language model generation, Wang et al.,
- Tree of Thoughts: Deliberate Problem Solving with Large Language Models, Yao et al.,
- Mistral 7B, Jiang et al.,
- Let's reward step by step: Step-Level reward model as the Navigators for Reasoning, Ma et al.,
- Camels in a changing climate: Enhancing lm adaptation with tulu 2, Ivison et al.,
- Towards Mitigating LLM Hallucination via Self Reflection, Ji et al.,
- Reasoning with Language Model is Planning with World Model, Hao et al.,
- Large Language Models are Better Reasoners with Self-Verification, Weng et al.,
- Reflexion: language agents with verbal reinforcement learning, Shinn et al.,
- Large Language Models Cannot Self-Correct Reasoning Yet, Huang et al.,
- Let's verify step by step, Lightman et al.,
- Mixtral of experts, Jiang et al.,
- Solving Challenging Math Word Problems Using GPT-4 Code Interpreter with Code-based Self-Verification, Zhou et al.,
- SelfCheck: Using LLMs to Zero-Shot Check Their Own Step-by-Step Reasoning, Miao et al.,
- Deepseek llm: Scaling open-source language models with longtermism, Bi et al.,
- Llemma: An Open Language Model for Mathematics, Azerbayev et al.,
- Deepseekmath: Pushing the limits of mathematical reasoning in open language models, Shao et al.,
- VerMCTS: Synthesizing Multi-Step Programs using a Verifier, a Large Language Model, and Tree Search, Brandfonbrener et al.,
- Can We Verify Step by Step for Incorrect Answer Detection?, Xu et al.,
- Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context, Team et al.,
- Internlm2 technical report, Cai et al.,
- Rewardbench: Evaluating reward models for language modeling, Lambert et al.,
- Uncertainty of Thoughts: Uncertainty-Aware Planning Enhances Information Seeking in Large Language Models, Hu et al.,
- Evaluating Mathematical Reasoning Beyond Accuracy, Xia et al.,
- Monte carlo tree search boosts reasoning via iterative preference learning, Xie et al.,
- Improving reward models with synthetic critiques, Ye et al.,
- Self-reflection in llm agents: Effects on problem-solving performance, Renze et al.,
- Rlhf workflow: From reward modeling to online rlhf, Dong et al.,
- Interactive Evolution: A Neural-Symbolic Self-Training Framework For Large Language Models, Xu et al.,
- Nemotron-4 340b technical report, Adler et al.,
- OVM, Outcome-supervised Value Models for Planning in Mathematical Reasoning, Yu et al.,
- The Reason behind Good or Bad: Towards a Better Mathematical Verifier with Natural Language Feedback, Gao et al.,
- Llm critics help catch bugs in mathematics: Towards a better mathematical verifier with natural language feedback, Gao et al.,
- Step-dpo: Step-wise preference optimization for long-chain reasoning of llms, Lai et al.,
- Llm critics help catch llm bugs, McAleese et al.,
- LLM Reasoners: New Evaluation, Library, and Analysis of Step-by-Step Reasoning with Large Language Models, Hao et al.,
- Token-Supervised Value Models for Enhancing Mathematical Reasoning Capabilities of Large Language Models, Lee et al.,
- Tlcr: Token-level continuous reward for fine-grained reinforcement learning from human feedback, Yoon et al.,
- The llama 3 herd of models, Dubey et al.,
- Mistral-NeMo-12B-Instruct, Team et al.,
- OffsetBias: Leveraging Debiased Data for Tuning Evaluators, Park et al.,
- Promptbreeder: Self-Referential Self-Improvement via Prompt Evolution, Fernando et al.,
- ReFT: Reasoning with Reinforced Fine-Tuning, Trung et al.,
- Self-Contrast: Better Reflection Through Inconsistent Solving Perspectives, Zhang et al.,
- Math-Shepherd: Verify and Reinforce LLMs Step-by-step without Human Annotations, Wang et al.,
- Selective Preference Optimization via Token-Level Reward Function Estimation, Yang et al.,
- When is Tree Search Useful for LLM Planning? It Depends on the Discriminator, Chen et al.,
- Self-taught evaluators, Wang et al.,
- Gemma 2: Improving open language models at a practical size, Team et al.,
- Generative verifiers: Reward modeling as next-token prediction, Zhang et al.,
- OpenCodeInterpreter: Integrating Code Generation with Execution and Refinement, Zheng et al.,
- Critic-cot: Boosting the reasoning abilities of large language model via chain-of-thoughts critic, Zheng et al.,
- Small Language Models Need Strong Verifiers to Self-Correct Reasoning, Zhang et al.,
- Abstract Meaning Representation-Based Logic-Driven Data Augmentation for Logical Reasoning, Bao et al.,
- Reasoning in Flux: Enhancing Large Language Models Reasoning through Uncertainty-aware Adaptive Guidance, Yin et al.,
- Direct Judgement Preference Optimization, Wang et al.,
- Unpacking DPO and PPO: Disentangling Best Practices for Learning from Preference Feedback, Ivison et al.,
- HelpSteer 2: Open-source dataset for training top-performing reward models, Wang et al.,
- Qwen2.5-math technical report: Toward mathematical expert model via self-improvement, Yang et al.,
- Critique-out-Loud Reward Models, Ankner et al.,
- Skywork-reward: Bag of tricks for reward modeling in llms, Liu et al.,
- On designing effective rl reward at training time for llm reasoning, Gao et al.,
- Reversal of Thought: Enhancing Large Language Models with Preference-Guided Reverse Reasoning Warm-up, Yuan et al.,
- Vineppo: Unlocking rl potential for llm reasoning through refined credit assignment, Kazemnejad et al.,
- Self-generated critiques boost reward modeling for language models, Yu et al.,
- Advancing Process Verification for Large Language Models via Tree-Based Preference Learning, He et al.,
- From generation to judgment: Opportunities and challenges of llm-as-a-judge, Li et al.,
- Search, Verify and Feedback: Towards Next Generation Post-training Paradigm of Foundation Models via Verifier Engineering, Guan et al.,
- Prometheus 2: An Open Source Language Model Specialized in Evaluating Other Language Models, Kim et al.,
- Foundational Autoraters: Taming Large Language Models for Better Automatic Evaluation, Vu et al.,
- Interpretable Preferences via Multi-Objective Reward Modeling and Mixture-of-Experts, Wang et al.,
- Step-level Value Preference Optimization for Mathematical Reasoning, Chen et al.,
- Skywork-o1 open series, Team et al.,
- Entropy-Regularized Process Reward Model, Zhang et al.,
- Llms-as-judges: a comprehensive survey on llm-based evaluation methods, Li et al.,
- Lmunit: Fine-grained evaluation with natural language unit tests, Saad-Falcon et al.,
- o1-coder: an o1 replication for coding, Zhang et al.,
- Hunyuanprover: A scalable data synthesis framework and guided tree search for automated theorem proving, Li et al.,
- Acemath: Advancing frontier math reasoning with post-training and reward modeling, Liu et al.,
- Free process rewards without process labels, Yuan et al.,
- AutoPSV: Automated Process-Supervised Verifier, Lu et al.,
- Processbench: Identifying process errors in mathematical reasoning, Zheng et al.,
- Qwen2.5 technical report, Yang et al.,
- Openai o1 system card, Jaech et al.,
- Outcome-Refining Process Supervision for Code Generation, Yu et al.,
- Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning, Guo et al.,
- Dynamic Scaling of Unit Tests for Code Reward Modeling, Ma et al.,
- What Makes Large Language Models Reason in (Multi-Turn) Code Generation?, Zheng et al.,
- Attention-guided Self-reflection for Zero-shot Hallucination Detection in Large Language Models, Liu et al.,
- Learning to Plan & Reason for Evaluation with Thinking-LLM-as-a-Judge, Saha et al.,
- Scaling Autonomous Agents via Automatic Reward Modeling And Planning, Chen et al.,
- Error Classification of Large Language Models on Math Word Problems: A Dynamically Adaptive Framework, Sun et al.,
- The lessons of developing process reward models in mathematical reasoning, Zhang et al.,
- Step-KTO: Optimizing Mathematical Reasoning through Stepwise Binary Feedback, Lin et al.,
- Physics of Language Models: Part 2.2, How to Learn From Mistakes on Grade-School Math Problems, Ye et al.,
- Advancing LLM Reasoning Generalists with Preference Trees, Yuan et al.,
- Rewarding Progress: Scaling Automated Process Verifiers for LLM Reasoning, Setlur et al.,
- Enabling Scalable Oversight via Self-Evolving Critic, Tang et al.,
- PRMBench: A Fine-grained and Challenging Benchmark for Process-Level Reward Models, Song et al.,
- Zero-Shot Verification-guided Chain of Thoughts, Chowdhury et al.,
- Robotic Programmer: Video Instructed Policy Code Generation for Robotic Manipulation, Xie et al.,
- Logic-RL: Unleashing LLM Reasoning with Rule-Based Reinforcement Learning, Xie et al.,
- SoRFT: Issue Resolving with Subtask-oriented Reinforced Fine-Tuning, Ma et al.,
- Training an LLM-as-a-Judge Model: Pipeline, Insights, and Practical Lessons, Hu et al.,
- Capturing Nuanced Preferences: Preference-Aligned Distillation for Small Language Models, Gu et al.,
- Distill Not Only Data but Also Rewards: Can Smaller Language Models Surpass Larger Ones?, Zhang et al.,
- Adaptivestep: Automatically dividing reasoning step through model confidence, Liu et al.,
- Unveiling and Causalizing CoT: A Causal Pespective, Fu et al.,
- Diverse Inference and Verification for Advanced Reasoning, Drori et al.,
- Mathematical Reasoning in Large Language Models: Assessing Logical and Arithmetic Errors across Wide Numerical Ranges, Shrestha et al.,
- A Survey on Feedback-based Multi-step Reasoning for Large Language Models on Mathematics, Wei et al.,
- Self-Consistency of the Internal Reward Models Improves Self-Rewarding Language Models, Zhou et al.,
- ACECODER: Acing Coder RL via Automated Test-Case Synthesis, Zeng et al.,
- A Study on Leveraging Search and Self-Feedback for Agent Reasoning, Yuan et al.,
- RefineCoder: Iterative Improving of Large Language Models via Adaptive Critique Refinement for Code Generation, Zhou et al.,
- Process Reward Models for LLM Agents: Practical Framework and Directions, Choudhury et al.,
- Process reinforcement through implicit rewards, Cui et al.,
- Full-Step-DPO: Self-Supervised Preference Optimization with Step-wise Rewards for Mathematical Reasoning, Xu et al.,
- VersaPRM: Multi-Domain Process Reward Model via Synthetic Reasoning Data, Zeng et al.,
- Direct Value Optimization: Improving Chain-of-Thought Reasoning in LLMs with Refined Values, Zhang et al.,
- Teaching Language Models to Critique via Reinforcement Learning, Xie et al.,
- Uncertainty-Aware Search and Value Models: Mitigating Search Scaling Flaws in LLMs, Yu et al.,
- AURORA: Automated Training Framework of Universal Process Reward Models via Ensemble Prompting and Reverse Verification, Tan et al.,
- Dyve: Thinking Fast and Slow for Dynamic Process Verification, Zhong et al.,
- Uncertainty-Aware Step-wise Verification with Generative Reward Models, Ye et al.,
- Visualprm: An effective process reward model for multimodal reasoning, Wang et al.,
- Monitoring Reasoning Models for Misbehavior and the Risks of Promoting Obfuscation, Baker et al.,
- An Efficient and Precise Training Data Construction Framework for Process-supervised Reward Model in Mathematical Reasoning, Sun et al.,
- JudgeLRM: Large Reasoning Models as a Judge, Chen et al.,
- QwQ: Reflect Deeply on the Boundaries of the Unknown, Team et al.,
Refinement
- Self-critiquing models for assisting human evaluators, Saunders et al.,
- Self-Refine: Iterative Refinement with Self-Feedback, Madaan et al.,
- Grace: Discriminator-guided chain-of-thought reasoning, Khalifa et al.,
- Automatically correcting large language models: Surveying the landscape of diverse self-correction strategies, Pan et al.,
- Learning from mistakes makes llm better reasoner, An et al.,
- Reflection-tuning: Data recycling improves llm instruction-tuning, Li et al.,
- Reflexion: language agents with verbal reinforcement learning, Shinn et al.,
- Towards Mitigating LLM Hallucination via Self Reflection, Ji et al.,
- SelfCheck: Using LLMs to Zero-Shot Check Their Own Step-by-Step Reasoning, Miao et al.,
- Teaching Large Language Models to Self-Debug, Chen et al.,
- Learning to check: Unleashing potentials for self-correction in large language models, Zhang et al.,
- REFINER: Reasoning Feedback on Intermediate Representations, Paul et al.,
- GLoRe: When, Where, and How to Improve LLM Reasoning via Global and Local Refinements, Havrilla et al.,
- Enhancing Zero-Shot Chain-of-Thought Reasoning in Large Language Models through Logic, Zhao et al.,
- General purpose verification for chain of thought prompting, Vacareanu et al.,
- Enhancing visual-language modality alignment in large vision language models via self-improvement, Wang et al.,
- Llm critics help catch bugs in mathematics: Towards a better mathematical verifier with natural language feedback, Gao et al.,
- Large language models have intrinsic self-correction ability, Liu et al.,
- Progressive-Hint Prompting Improves Reasoning in Large Language Models, Zheng et al.,
- Accessing gpt-4 level mathematical olympiad solutions via monte carlo tree self-refine with llama-3 8b, Zhang et al.,
- Toward Adaptive Reasoning in Large Language Models with Thought Rollback, Chen et al.,
- CoT Rerailer: Enhancing the Reliability of Large Language Models in Complex Reasoning Tasks through Error Detection and Correction, Wan et al.,
- Pride and Prejudice: LLM Amplifies Self-Bias in Self-Refinement, Xu et al.,
- Mutual reasoning makes smaller llms stronger problem-solvers, Qi et al.,
- S 3 c-Math: Spontaneous Step-level Self-correction Makes Large Language Models Better Mathematical Reasoners, Yan et al.,
- Training language models to self-correct via reinforcement learning, Kumar et al.,
- A Theoretical Understanding of Self-Correction through In-context Alignment, Wang et al.,
- ReST-MCTS*: LLM Self-Training via Process Reward Guided Tree Search, Zhang et al.,
- Recursive Introspection: Teaching Language Model Agents How to Self-Improve, Qu et al.,
- Enhancing Mathematical Reasoning in LLMs by Stepwise Correction, Wu et al.,
- LLM Self-Correction with DeCRIM: Decompose, Critique, and Refine for Enhanced Following of Instructions with Multiple Constraints, Ferraz et al.,
- O1 Replication Journey: A Strategic Progress Report--Part 1, Qin et al.,
- Advancing Large Language Model Attribution through Self-Improving, Huang et al.,
- Enhancing llm reasoning via critique models with test-time and training-time supervision, Xi et al.,
- Vision-language models can self-improve reasoning via reflection, Cheng et al.,
- Confidence vs Critique: A Decomposition of Self-Correction Capability for LLMs, Yang et al.,
- LLM2: Let Large Language Models Harness System 2 Reasoning, Yang et al.,
- Understanding the Dark Side of LLMs' Intrinsic Self-Correction, Zhang et al.,
- Enhancing LLM Reasoning with Multi-Path Collaborative Reactive and Reflection agents, He et al.,
- CoT-based Synthesizer: Enhancing LLM Performance through Answer Synthesis, Zhang et al.,
- Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning, Guo et al.,
- 7B Model and 8K Examples: Emerging Reasoning with Reinforcement Learning is Both Effective and Efficient, Zeng et al.,
- BackMATH: Towards Backward Reasoning for Solving Math Problems Step by Step, Zhang et al.,
- ReARTeR: Retrieval-Augmented Reasoning with Trustworthy Process Rewarding, Sun et al.,
- Critique fine-tuning: Learning to critique is more effective than learning to imitate, Wang et al.,
- RealCritic: Towards Effectiveness-Driven Evaluation of Language Model Critiques, Tang et al.,
- ProgCo: Program Helps Self-Correction of Large Language Models, Song et al.,
- URSA: Understanding and Verifying Chain-of-thought Reasoning in Multimodal Mathematics, Luo et al.,
- S2R: Teaching LLMs to Self-verify and Self-correct via Reinforcement Learning, Ma et al.,
- ReasonFlux: Hierarchical LLM Reasoning via Scaling Thought Templates, Yang et al.,
- ReVISE: Learning to Refine at Test-Time via Intrinsic Self-Verification, Lee et al.,
- Step Back to Leap Forward: Self-Backtracking for Boosting Reasoning of Language Models, Yang et al.,
- Iterative Deepening Sampling for Large Language Models, Chen et al.,
- LLMs Can Easily Learn to Reason from Demonstrations Structure, not content, is what matters!, Li et al.,
- MM-Verify: Enhancing Multimodal Reasoning with Chain-of-Thought Verification, Sun et al.,
- ARIES: Stimulating Self-Refinement of Large Language Models by Iterative Preference Optimization, Zeng et al.,
- Optimizing generative AI by backpropagating language model feedback, Yuksekgonul et al.,
- DLPO: Towards a Robust, Efficient, and Generalizable Prompt Optimization Framework from a Deep-Learning Perspective, Peng et al.,
- Instruct-of-Reflection: Enhancing Large Language Models Iterative Reflection Capabilities via Dynamic-Meta Instruction, Liu et al.,
- The Lighthouse of Language: Enhancing LLM Agents via Critique-Guided Improvement, Yang et al.,
Extensive Exploration
Exploration Scaling
- Greedy Policy Search: A Simple Baseline for Learnable Test-Time Augmentation, Lyzhov et al.,
- Scaling scaling laws with board games, Jones et al.,
- Show Your Work: Scratchpads for Intermediate Computation with Language Models, Nye et al.,
- Complexity-Based Prompting for Multi-step Reasoning, Fu et al.,
- Self-Consistency Improves Chain of Thought Reasoning in Language Models, Wang et al.,
- Making Language Models Better Reasoners with Step-Aware Verifier, Li et al.,
- Deductive Verification of Chain-of-Thought Reasoning, Ling et al.,
- Cross-lingual Prompting: Improving Zero-shot Chain-of-Thought Reasoning across Languages, Qin et al.,
- Don't Trust: Verify -- Grounding LLM Quantitative Reasoning with Autoformalization, Zhou et al.,
- Multi-step problem solving through a verifier: An empirical analysis on model-induced process supervision, Wang et al.,
- Stepwise self-consistent mathematical reasoning with large language models, Zhao et al.,
- General purpose verification for chain of thought prompting, Vacareanu et al.,
- Improve Mathematical Reasoning in Language Models by Automated Process Supervision, Luo et al.,
- Large language monkeys: Scaling inference compute with repeated sampling, Brown et al.,
- Scaling llm test-time compute optimally can be more effective than scaling model parameters, Snell et al.,
- Inference scaling laws: An empirical analysis of compute-optimal inference for problem-solving with language models, Wu et al.,
- Learning to Reason via Program Generation, Emulation, and Search, Weir et al.,
- What are the essential factors in crafting effective long context multi-hop instruction datasets? insights and best practices, Chen et al.,
- MAgICoRe: Multi-Agent, Iterative, Coarse-to-Fine Refinement for Reasoning, Chen et al.,
- Scaling llm inference with optimized sample compute allocation, Zhang et al.,
- Rlef: Grounding code llms in execution feedback with reinforcement learning, Gehring et al.,
- Planning in Natural Language Improves LLM Search for Code Generation, Wang et al.,
- Beyond examples: High-level automated reasoning paradigm in in-context learning via mcts, Wu et al.,
- Python is Not Always the Best Choice: Embracing Multilingual Program of Thoughts, Luo et al.,
- From Decoding to Meta-Generation: Inference-time Algorithms for Large Language Models, Welleck et al.,
- From medprompt to o1: Exploration of run-time strategies for medical challenge problems and beyond, Nori et al.,
- Wrong-of-Thought: An Integrated Reasoning Framework with Multi-Perspective Verification and Wrong Information, Zhang et al.,
- A simple and provable scaling law for the test-time compute of large language models, Chen et al.,
- Openai o1 system card, Jaech et al.,
- Lachesis: Predicting LLM Inference Accuracy using Structural Properties of Reasoning Paths, Kim et al.,
- Seed-cts: Unleashing the power of tree search for superior performance in competitive coding tasks, Wang et al.,
- Inference Scaling vs Reasoning: An Empirical Analysis of Compute-Optimal LLM Problem-Solving, AbdElhameed et al.,
- s1: Simple test-time scaling, Muennighoff et al.,
- From Drafts to Answers: Unlocking LLM Potential via Aggregation Fine-Tuning, Li et al.,
- Chain-of-Reasoning: Towards Unified Mathematical Reasoning in Large Language Models via a Multi-Paradigm Perspective, Yu et al.,
- Test-time Computing: from System-1 Thinking to System-2 Thinking, Ji et al.,
- SETS: Leveraging Self-Verification and Self-Correction for Improved Test-Time Scaling, Chen et al.,
- Instantiation-based Formalization of Logical Reasoning Tasks using Language Models and Logical Solvers, Raza et al.,
- The lessons of developing process reward models in mathematical reasoning, Zhang et al.,
- ExACT: Teaching AI Agents to Explore with Reflective-MCTS and Exploratory Learning, Yu et al.,
- ECM: A Unified Electronic Circuit Model for Explaining the Emergence of In-Context Learning and Chain-of-Thought in Large Language Model, Chen et al.,
- Scaling up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach, Geiping et al.,
- Inner Thinking Transformer: Leveraging Dynamic Depth Scaling to Foster Adaptive Internal Thinking, Chen et al.,
- Scalable Best-of-N Selection for Large Language Models via Self-Certainty, Kang et al.,
- Can 1B LLM Surpass 405B LLM? Rethinking Compute-Optimal Test-Time Scaling, Liu et al.,
- Revisiting the Test-Time Scaling of o1-like Models: Do they Truly Possess Test-Time Scaling Capabilities?, Zeng et al.,
- Optimizing Temperature for Language Models with Multi-Sample Inference, Du et al.,
- Bag of Tricks for Inference-time Computation of LLM Reasoning, Liu et al.,
- Towards Thinking-Optimal Scaling of Test-Time Compute for LLM Reasoning, Yang et al.,
- (Mis) Fitting: A Survey of Scaling Laws, Li et al.,
- METAL: A Multi-Agent Framework for Chart Generation with Test-Time Scaling, Li et al.,
- Reasoning-as-Logic-Units: Scaling Test-Time Reasoning in Large Language Models Through Logic Unit Alignment, Li et al.,
- Sample, Scrutinize and Scale: Effective Inference-Time Search by Scaling Verification, Zhao et al.,
- TestNUC: Enhancing Test-Time Computing Approaches through Neighboring Unlabeled Data Consistency, Zou et al.,
- Confidence Improves Self-Consistency in LLMs, Taubenfeld et al.,
- S*: Test Time Scaling for Code Generation, Li et al.,
- Bridging Internal Probability and Self-Consistency for Effective and Efficient LLM Reasoning, Zhou et al.,
- Is Depth All You Need? An Exploration of Iterative Reasoning in LLMs, Wu et al.,
- Think Twice: Enhancing LLM Reasoning by Scaling Multi-round Test-time Thinking, Tian et al.,
- What, How, Where, and How Well? A Survey on Test-Time Scaling in Large Language Models, Zhang et al.,
- Metascale: Test-time scaling with evolving meta-thoughts, Liu et al.,
- Multidimensional Consistency Improves Reasoning in Language Models, Lai et al.,
- Efficient test-time scaling via self-calibration, Huang et al.,
- Do We Truly Need So Many Samples? Multi-LLM Repeated Sampling Efficiently Scale Test-Time Compute, Chen et al.,
External Exploration
- Competition-Level Code Generation with AlphaCode, Li et al.,
- Least-to-Most Prompting Enables Complex Reasoning in Large Language Models, Zhou et al.,
- Llama: Open and efficient foundation language models, Touvron et al.,
- Gpt-4 technical report, Achiam et al.,
- Llama 2: Open foundation and fine-tuned chat models, Touvron et al.,
- Code llama: Open foundation models for code, Roziere et al.,
- Self-Evaluation Guided Beam Search for Reasoning, Xie et al.,
- No train still gain. unleash mathematical reasoning of large language models with monte carlo tree search guided by energy function, Xu et al.,
- Tree of Thoughts: Deliberate Problem Solving with Large Language Models, Yao et al.,
- Tora: A tool-integrated reasoning agent for mathematical problem solving, Gou et al.,
- Mistral 7B, Jiang et al.,
- Mathcoder: Seamless code integration in llms for enhanced mathematical reasoning, Wang et al.,
- PATHFINDER: Guided Search over Multi-Step Reasoning Paths, Golovneva et al.,
- Reflexion: language agents with verbal reinforcement learning, Shinn et al.,
- Reasoning with Language Model is Planning with World Model, Hao et al.,
- The claude 3 model family: Opus, sonnet, haiku, Anthropic et al.,
- NuminaMath, LI et al.,
- Demystifying chains, trees, and graphs of thoughts, Besta et al.,
- MARIO: MAth Reasoning with code Interpreter Output--A Reproducible Pipeline, Liao et al.,
- Deepseekmath: Pushing the limits of mathematical reasoning in open language models, Shao et al.,
- Mathgenie: Generating synthetic data with question back-translation for enhancing mathematical reasoning of llms, Lu et al.,
- Graph of Thoughts: Solving Elaborate Problems with Large Language Models, Besta et al.,
- Tree of Uncertain Thoughts Reasoning for Large Language Models, Mo et al.,
- Mindstar: Enhancing math reasoning in pre-trained llms at inference time, Kang et al.,
- Mapcoder: Multi-agent code generation for competitive problem solving, Islam et al.,
- AlphaZero-Like Tree-Search can Guide Large Language Model Decoding and Training, Wan et al.,
- Monte carlo tree search boosts reasoning via iterative preference learning, Xie et al.,
- Accessing gpt-4 level mathematical olympiad solutions via monte carlo tree self-refine with llama-3 8b, Zhang et al.,
- Strategist: Learning Strategic Skills by LLMs via Bi-Level Tree Search, Light et al.,
- Deductive Beam Search: Decoding Deducible Rationale for Chain-of-Thought Reasoning, Zhu et al.,
- Beyond A*: Better Planning with Transformers via Search Dynamics Bootstrapping, Lehnert et al.,
- Don't throw away your value model! Generating more preferable text with Value-Guided Monte-Carlo Tree Search decoding, Liu et al.,
- Qwen2 Technical Report, Yang et al.,
- The llama 3 herd of models, Dubey et al.,
- Litesearch: Efficacious tree search for llm, Wang et al.,
- LLM Reasoners: New Evaluation, Library, and Analysis of Step-by-Step Reasoning with Large Language Models, Hao et al.,
- Tree search for language model agents, Koh et al.,
- GraphReason: Enhancing Reasoning Capabilities of Large Language Models through A Graph-Based Verification Approach, Cao et al.,
- Agent q: Advanced reasoning and learning for autonomous ai agents, Putta et al.,
- Making PPO even better: Value-Guided Monte-Carlo Tree Search decoding, Liu et al.,
- Toward Self-Improvement of LLMs via Imagination, Searching, and Criticizing, Tian et al.,
- On the diagram of thought, Zhang et al.,
- Qwen2.5-math technical report: Toward mathematical expert model via self-improvement, Yang et al.,
- AlphaMath Almost Zero: Process Supervision without Process, Chen et al.,
- RethinkMCTS: Refining Erroneous Thoughts in Monte Carlo Tree Search for Code Generation, Li et al.,
- Fine-Tuning Large Vision-Language Models as Decision-Making Agents via Reinforcement Learning, Zhai et al.,
- Llama-berry: Pairwise optimization for o1-like olympiad-level mathematical reasoning, Zhang et al.,
- Understanding When Tree of Thoughts Succeeds: Larger Models Excel in Generation, Not Discrimination, Chen et al.,
- Treebon: Enhancing inference-time alignment with speculative tree-search and best-of-n sampling, Qiu et al.,
- Towards Self-Improvement of LLMs via MCTS: Leveraging Stepwise Knowledge with Curriculum Preference Learning, Wang et al.,
- Aflow: Automating agentic workflow generation, Zhang et al.,
- Cooperative Strategic Planning Enhances Reasoning Capabilities in Large Language Models, Wang et al.,
- Deliberate reasoning for llms as structure-aware planning with accurate world model, Xiong et al.,
- Enhancing multi-step reasoning abilities of language models through direct q-function optimization, Liu et al.,
- Process reward model with q-value rankings, Li et al.,
- Scattered Forest Search: Smarter Code Space Exploration with LLMs, Light et al.,
- AtomThink: A Slow Thinking Framework for Multimodal Mathematical Reasoning, Xiang et al.,
- On the Empirical Complexity of Reasoning and Planning in LLMs, Kang et al.,
- CodeTree: Agent-guided Tree Search for Code Generation with Large Language Models, Li et al.,
- Technical report: Enhancing llm reasoning with reward-guided tree search, Jiang et al.,
- SRA-MCTS: Self-driven Reasoning Aurmentation with Monte Carlo Tree Search for Enhanced Code Generation, Xu et al.,
- Marco-o1: Towards open reasoning models for open-ended solutions, Zhao et al.,
- GPT-Guided Monte Carlo Tree Search for Symbolic Regression in Financial Fraud Detection, Kadam et al.,
- MC-NEST--Enhancing Mathematical Reasoning in Large Language Models with a Monte Carlo Nash Equilibrium Self-Refine Tree, Rabby et al.,
- SPaR: Self-Play with Tree-Search Refinement to Improve Instruction-Following in Large Language Models, Cheng et al.,
- Forest-of-thought: Scaling test-time compute for enhancing LLM reasoning, Bi et al.,
- Mulberry: Empowering mllm with o1-like reasoning and reflection via collective monte carlo tree search, Yao et al.,
- Tree-of-Code: A Tree-Structured Exploring Framework for End-to-End Code Generation and Execution in Complex Task Handling, Ni et al.,
- LLM2: Let Large Language Models Harness System 2 Reasoning, Yang et al.,
- Towards Intrinsic Self-Correction Enhancement in Monte Carlo Tree Search Boosted Reasoning via Iterative Preference Learning, Jiang et al.,
- Ensembling Large Language Models with Process Reward-Guided Tree Search for Better Complex Reasoning, Park et al.,
- rStar-Math: Small LLMs Can Master Math Reasoning with Self-Evolved Deep Thinking, Guan et al.,
- Evolving Deeper LLM Thinking, Lee et al.,
- A Roadmap to Guide the Integration of LLMs in Hierarchical Planning, Puerta-Merino et al.,
- BoostStep: Boosting mathematical capability of Large Language Models via improved single-step reasoning, Zhang et al.,
- Monte Carlo Tree Search for Comprehensive Exploration in LLM-Based Automatic Heuristic Design, Zheng et al.,
- Leveraging Constrained Monte Carlo Tree Search to Generate Reliable Long Chain-of-Thought for Mathematical Reasoning, Lin et al.,
- A Probabilistic Inference Approach to Inference-Time Scaling of LLMs using Particle-Based Monte Carlo Methods, Puri et al.,
- Hypothesis-Driven Theory-of-Mind Reasoning for Large Language Models, Kim et al.,
- SIFT: Grounding LLM Reasoning in Contexts via Stickers, Zeng et al.,
- Atom of Thoughts for Markov LLM Test-Time Scaling, Teng et al.,
- Reasoning with Reinforced Functional Token Tuning, Zhang et al.,
- CoAT: Chain-of-Associated-Thoughts Framework for Enhancing Large Language Models Reasoning, Pan et al.,
- MAPoRL: Multi-Agent Post-Co-Training for Collaborative Large Language Models with Reinforcement Learning, Park et al.,
- QLASS: Boosting Language Agent Inference via Q-Guided Stepwise Search, Lin et al.,
- CritiQ: Mining Data Quality Criteria from Human Preferences, Guo et al.,
- START: Self-taught Reasoner with Tools, Li et al.,
- Better Process Supervision with Bi-directional Rewarding Signals, Chen et al.,
Internal Exploration
- Policy Gradient Methods for Reinforcement Learning with Function Approximation, Sutton et al.,
- Proximal policy optimization algorithms, Schulman et al.,
- Training verifiers to solve math word problems, Cobbe et al.,
- Direct preference optimization: Your language model is secretly a reward model, Rafailov et al.,
- Gpt-4 technical report, Achiam et al.,
- The claude 3 model family: Opus, sonnet, haiku, Anthropic et al.,
- Deepseekmath: Pushing the limits of mathematical reasoning in open language models, Shao et al.,
- Kto: Model alignment as prospect theoretic optimization, Ethayarajh et al.,
- Stepcoder: Improve code generation with reinforcement learning from compiler feedback, Dou et al.,
- Beyond Human Data: Scaling Self-Training for Problem-Solving with Language Models, Singh et al.,
- ReMax: A Simple, Effective, and Efficient Reinforcement Learning Method for Aligning Large Language Models, Li et al.,
- AlphaZero-Like Tree-Search can Guide Large Language Model Decoding and Training, Wan et al.,
- Chatglm: A family of large language models from glm-130b to glm-4 all tools, GLM et al.,
- The llama 3 herd of models, Dubey et al.,
- RL on Incorrect Synthetic Data Scales the Efficiency of LLM Math Reasoning by Eight-Fold, Setlur et al.,
- CPL: Critical Plan Step Learning Boosts LLM Generalization in Reasoning Tasks, Wang et al.,
- Unpacking DPO and PPO: Disentangling Best Practices for Learning from Preference Feedback, Ivison et al.,
- Qwen2.5-coder technical report, Hui et al.,
- Qwen2.5-math technical report: Toward mathematical expert model via self-improvement, Yang et al.,
- Building math agents with multi-turn iterative preference learning, Xiong et al.,
- Unlocking the Capabilities of Thought: A Reasoning Boundary Framework to Quantify and Optimize Chain-of-Thought, Chen et al.,
- ReST-MCTS*: LLM Self-Training via Process Reward Guided Tree Search, Zhang et al.,
- A Small Step Towards Reproducing OpenAI o1: Progress Report on the Steiner Open Source Models, Ji et al.,
- A Comprehensive Survey of Direct Preference Optimization: Datasets, Theories, Variants, and Applications, Xiao et al.,
- OpenMathInstruct-2: Accelerating AI for Math with Massive Open-Source Instruction Data, Toshniwal et al.,
- Critical Tokens Matter: Token-Level Contrastive Estimation Enhence LLM's Reasoning Capability, Lin et al.,
- Improving Multi-Step Reasoning Abilities of Large Language Models with Direct Advantage Policy Optimization, Liu et al.,
- o1-coder: an o1 replication for coding, Zhang et al.,
- Offline Reinforcement Learning for LLM Multi-Step Reasoning, Wang et al.,
- Qwen2.5 technical report, Yang et al.,
- Deepseek-v3 technical report, Liu et al.,
- Openai o1 system card, Jaech et al.,
- Sft memorizes, rl generalizes: A comparative study of foundation model post-training, Chu et al.,
- REINFORCE++: A Simple and Efficient Approach for Aligning Large Language Models, Hu et al.,
- Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning, Guo et al.,
- Advancing Language Model Reasoning through Reinforcement Learning and Inference Scaling, Hou et al.,
- Diverse Preference Optimization, Lanchantin et al.,
- COS (M+ O) S: Curiosity and RL-Enhanced MCTS for Exploring Story Space via Language Models, Materzok et al.,
- 7B Model and 8K Examples: Emerging Reasoning with Reinforcement Learning is Both Effective and Efficient, Zeng et al.,
- Search-o1: Agentic search-enhanced large reasoning models, Li et al.,
- rStar-Math: Small LLMs Can Master Math Reasoning with Self-Evolved Deep Thinking, Guan et al.,
- Kimi k1. 5: Scaling reinforcement learning with llms, Team et al.,
- Satori: Reinforcement Learning with Chain-of-Action-Thought Enhances LLM Reasoning via Autoregressive Search, Shen et al.,
- Demystifying Long Chain-of-Thought Reasoning in LLMs, Yeo et al.,
- LIMR: Less is More for RL Scaling, Li et al.,
- Ignore the KL Penalty! Boosting Exploration on Critical Tokens to Enhance RL Fine-Tuning, Vassoyan et al.,
- Lean and Mean: Decoupled Value Policy Optimization with Global Value Guidance, Huang et al.,
- Process reinforcement through implicit rewards, Cui et al.,
- SPPD: Self-training with Process Preference Learning Using Dynamic Value Margin, Yi et al.,
- Logic-RL: Unleashing LLM Reasoning with Rule-Based Reinforcement Learning, Xie et al.,
- Towards Thinking-Optimal Scaling of Test-Time Compute for LLM Reasoning, Yang et al.,
- Training Language Models to Reason Efficiently, Arora et al.,
- LLM Post-Training: A Deep Dive into Reasoning Large Language Models, Kumar et al.,
- Reward-aware Preference Optimization: A Unified Mathematical Framework for Model Alignment, Sun et al.,
- Focused-DPO: Enhancing Code Generation Through Focused Preference Optimization on Error-Prone Points, Zhang et al.,
- Reasoning with Reinforced Functional Token Tuning, Zhang et al.,
- Qsharp: Provably Optimal Distributional RL for LLM Post-Training, Zhou et al.,
- Exploring the Limit of Outcome Reward for Learning Mathematical Reasoning, Lyu et al.,
- Competitive Programming with Large Reasoning Models, El-Kishky et al.,
- SWE-RL: Advancing LLM Reasoning via Reinforcement Learning on Open Software Evolution, Wei et al.,
- Inference-Time Computations for LLM Reasoning and Planning: A Benchmark and Insights, Parashar et al.,
- Metastable Dynamics of Chain-of-Thought Reasoning: Provable Benefits of Search, RL and Distillation, Kim et al.,
- On the Emergence of Thinking in LLMs I: Searching for the Right Intuition, Ye et al.,
- The Danger of Overthinking: Examining the Reasoning-Action Dilemma in Agentic Tasks, Cuadron et al.,
- DeepScaleR: Surpassing O1-Preview with a 1.5B Model by Scaling RL, Luo et al.,
- STeCa: Step-level Trajectory Calibration for LLM Agent Learning, Wang et al.,
- Thinking Preference Optimization, Yang et al.,
- Trajectory Balance with Asynchrony: Decoupling Exploration and Learning for Fast, Scalable LLM Post-Training, Bartoldson et al.,
- Dapo: An open-source llm reinforcement learning system at scale, Yu et al.,
- Open-Reasoner-Zero: An Open Source Approach to Scaling Up Reinforcement Learning on the Base Model, Hu et al.,
- Optimizing Test-Time Compute via Meta Reinforcement Finetuning, Qu et al.,
- Reinforcement Learning for Reasoning in Small LLMs: What Works and What Doesn't, Dang et al.,
- SWEET-RL: Training Multi-Turn LLM Agents on Collaborative Reasoning Tasks, Zhou et al.,
- START: Self-taught Reasoner with Tools, Li et al.,
- Expanding RL with Verifiable Rewards Across Diverse Domains, Su et al.,
- R-PRM: Reasoning-Driven Process Reward Modeling, She et al.,
- VAPO: Efficient and Reliable Reinforcement Learning for Advanced Reasoning Tasks, YuYue et al.,
- Z1: Efficient Test-time Scaling with Code, Yu et al.,
- QwQ: Reflect Deeply on the Boundaries of the Unknown, Team et al.,
Future and Frontiers
Agentic & Embodied Long CoT
- Solving Math Word Problems via Cooperative Reasoning induced Language Models, Zhu et al.,
- Reasoning with Language Model is Planning with World Model, Hao et al.,
- Large language models as commonsense knowledge for large-scale task planning, Zhao et al.,
- Robotic Control via Embodied Chain-of-Thought Reasoning, Zawalski et al.,
- Tree-Planner: Efficient Close-loop Task Planning with Large Language Models, Hu et al.,
- Language Agent Tree Search Unifies Reasoning, Acting, and Planning in Language Models, Zhou et al.,
- Strategist: Learning Strategic Skills by LLMs via Bi-Level Tree Search, Light et al.,
- Mixture-of-agents enhances large language model capabilities, Wang et al.,
- ADaPT: As-Needed Decomposition and Planning with Language Models, Prasad et al.,
- Tree search for language model agents, Koh et al.,
- Hiagent: Hierarchical working memory management for solving long-horizon agent tasks with large language model, Hu et al.,
- S3 agent: Unlocking the power of VLLM for zero-shot multi-modal sarcasm detection, Wang et al.,
- MACM: Utilizing a Multi-Agent System for Condition Mining in Solving Complex Mathematical Problems, Lei et al.,
- Fine-Tuning Large Vision-Language Models as Decision-Making Agents via Reinforcement Learning, Zhai et al.,
- EVOLvE: Evaluating and Optimizing LLMs For Exploration, Nie et al.,
- Agents Thinking Fast and Slow: A Talker-Reasoner Architecture, Christakopoulou et al.,
- Robotic Programmer: Video Instructed Policy Code Generation for Robotic Manipulation, Xie et al.,
- Titans: Learning to memorize at test time, Behrouz et al.,
- Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success, Kim et al.,
- World Modeling Makes a Better Planner: Dual Preference Optimization for Embodied Task Planning, Wang et al.,
- Embodied-Reasoner: Synergizing Visual Search, Reasoning, and Action for Embodied Interactive Tasks, Zhang et al.,
- Cosmos-reason1: From physical common sense to embodied reasoning, Azzolini et al.,
- Improving Retrospective Language Agents via Joint Policy Gradient Optimization, Feng et al.,
- Haste Makes Waste: Evaluating Planning Abilities of LLMs for Efficient and Feasible Multitasking with Time Constraints Between Actions, Wu et al.,
- MultiAgentBench: Evaluating the Collaboration and Competition of LLM agents, Zhu et al.,
- ReMA: Learning to Meta-think for LLMs with Multi-Agent Reinforcement Learning, Wan et al.,
- MAS-GPT: Training LLMs To Build LLM-Based Multi-Agent Systems, Ye et al.,
- Advances and Challenges in Foundation Agents: From Brain-Inspired Intelligence to Evolutionary, Collaborative, and Safe Systems, Liu et al.,
Efficient Long CoT
- Guiding language model reasoning with planning tokens, Wang et al.,
- Synergy-of-thoughts: Eliciting efficient reasoning in hybrid language models, Shang et al.,
- Distilling system 2 into system 1, Yu et al.,
- Concise thoughts: Impact of output length on llm reasoning and cost, Nayab et al.,
- Litesearch: Efficacious tree search for llm, Wang et al.,
- Uncertainty-Guided Optimization on Large Language Model Search Trees, Grosse et al.,
- CPL: Critical Plan Step Learning Boosts LLM Generalization in Reasoning Tasks, Wang et al.,
- Unlocking the Capabilities of Thought: A Reasoning Boundary Framework to Quantify and Optimize Chain-of-Thought, Chen et al.,
- Kvsharer: Efficient inference via layer-wise dissimilar KV cache sharing, Yang et al.,
- Interpretable contrastive monte carlo tree search reasoning, Gao et al.,
- Dualformer: Controllable fast and slow thinking by learning with randomized reasoning traces, Su et al.,
- DynaThink: Fast or Slow? A Dynamic Decision-Making Framework for Large Language Models, Pan et al.,
- Language models are hidden reasoners: Unlocking latent reasoning capabilities via self-rewarding, Chen et al.,
- Token-budget-aware llm reasoning, Han et al.,
- B-STaR: Monitoring and Balancing Exploration and Exploitation in Self-Taught Reasoners, Zeng et al.,
- C3oT: Generating Shorter Chain-of-Thought without Compromising Effectiveness, Kang et al.,
- Training large language models to reason in a continuous latent space, Hao et al.,
- CoMT: A Novel Benchmark for Chain of Multi-modal Thought on Large Vision-Language Models, Cheng et al.,
- Kimi k1. 5: Scaling reinforcement learning with llms, Team et al.,
- O1-Pruner: Length-Harmonizing Fine-Tuning for O1-Like Reasoning Pruning, Luo et al.,
- Reward-Guided Speculative Decoding for Efficient LLM Reasoning, Liao et al.,
- Think Smarter not Harder: Adaptive Reasoning with Inference Aware Optimization, Yu et al.,
- Efficient Reasoning with Hidden Thinking, Shen et al.,
- On the Query Complexity of Verifier-Assisted Language Generation, Botta et al.,
- TokenSkip: Controllable Chain-of-Thought Compression in LLMs, Xia et al.,
- Boost, Disentangle, and Customize: A Robust System2-to-System1 Pipeline for Code Generation, Du et al.,
- Jakiro: Boosting Speculative Decoding with Decoupled Multi-Head via MoE, Huang et al.,
- Towards Reasoning Ability of Small Language Models, Srivastava et al.,
- Towards Economical Inference: Enabling DeepSeek's Multi-Head Latent Attention in Any Transformer-based LLMs, Ji et al.,
- Portable Reward Tuning: Towards Reusable Fine-Tuning across Different Pretrained Models, Chijiwa et al.,
- MM-Verify: Enhancing Multimodal Reasoning with Chain-of-Thought Verification, Sun et al.,
- Language Models Can Predict Their Own Behavior, Ashok et al.,
- On the Convergence Rate of MCTS for the Optimal Value Estimation in Markov Decision Processes, Chang et al.,
- CoT-Valve: Length-Compressible Chain-of-Thought Tuning, Ma et al.,
- Training Language Models to Reason Efficiently, Arora et al.,
- Chain of Draft: Thinking Faster by Writing Less, Xu et al.,
- Learning to Stop Overthinking at Test Time, Bao et al.,
- Self-Training Elicits Concise Reasoning in Large Language Models, Munkhbat et al.,
- Length-Controlled Margin-Based Preference Optimization without Reference Model, Li et al.,
- Reasoning on a Spectrum: Aligning LLMs to System 1 and System 2 Thinking, Ziabari et al.,
- Dynamic Parallel Tree Search for Efficient LLM Reasoning, Ding et al.,
- Stepwise Perplexity-Guided Refinement for Efficient Chain-of-Thought Reasoning in Large Language Models, Cui et al.,
- Dynamic Chain-of-Thought: Towards Adaptive Deep Reasoning, Wang et al.,
- SoftCoT: Soft Chain-of-Thought for Efficient Reasoning with LLMs, Xu et al.,
- LightThinker: Thinking Step-by-Step Compression, Zhang et al.,
- Position: Multimodal Large Language Models Can Significantly Advance Scientific Reasoning, Yan et al.,
- Stepwise Informativeness Search for Improving LLM Reasoning, Wang et al.,
- Adaptive Group Policy Optimization: Towards Stable Training and Token-Efficient Reasoning, Li et al.,
- Innate Reasoning is Not Enough: In-Context Learning Enhances Reasoning Large Language Models with Less Overthinking, Ge et al.,
- Understanding r1-zero-like training: A critical perspective, Liu et al.,
- The First Few Tokens Are All You Need: An Efficient and Effective Unsupervised Prefix Fine-Tuning Method for Reasoning Models, Ji et al.,
- L1: Controlling How Long A Reasoning Model Thinks With Reinforcement Learning, Aggarwal et al.,
- DAST: Difficulty-Adaptive Slow-Thinking for Large Reasoning Models, Shen et al.,
- ThinkPrune: Pruning Long Chain-of-Thought of LLMs via Reinforcement Learning, Hou et al.,
Knowledge-Augmented Long CoT
- Best of Both Worlds: Harmonizing LLM Capabilities in Decision-Making and Question-Answering for Treatment Regimes, Liu et al.,
- Understanding Reasoning Ability of Language Models From the Perspective of Reasoning Paths Aggregation, Wang et al.,
- Stream of search (sos): Learning to search in language, Gandhi et al.,
- CoPS: Empowering LLM Agents with Provable Cross-Task Experience Sharing, Yang et al.,
- Disentangling memory and reasoning ability in large language models, Jin et al.,
- Huatuogpt-o1, towards medical complex reasoning with llms, Chen et al.,
- RAG-Star: Enhancing Deliberative Reasoning with Retrieval Augmented Verification and Refinement, Jiang et al.,
- O1 Replication Journey--Part 3: Inference-time Scaling for Medical Reasoning, Huang et al.,
- MedS 3: Towards Medical Small Language Models with Self-Evolved Slow Thinking, Jiang et al.,
- Search-o1: Agentic search-enhanced large reasoning models, Li et al.,
- Chain-of-Retrieval Augmented Generation, Wang et al.,
- Evaluating Large Language Models through Role-Guide and Self-Reflection: A Comparative Study, Zhao et al.,
- Citrus: Leveraging Expert Cognitive Pathways in a Medical Language Model for Advanced Medical Decision Support, Wang et al.,
- ECM: A Unified Electronic Circuit Model for Explaining the Emergence of In-Context Learning and Chain-of-Thought in Large Language Model, Chen et al.,
- Large Language Models for Recommendation with Deliberative User Preference Alignment, Fang et al.,
- ChineseEcomQA: A Scalable E-commerce Concept Evaluation Benchmark for Large Language Models, Chen et al.,
- DeepRAG: Thinking to Retrieval Step by Step for Large Language Models, Guan et al.,
- Open Deep Research, Team et al.,
- HopRAG: Multi-Hop Reasoning for Logic-Aware Retrieval-Augmented Generation, Liu et al.,
- O1 Embedder: Let Retrievers Think Before Action, Yan et al.,
- MedVLM-R1: Incentivizing Medical Reasoning Capability of Vision-Language Models (VLMs) via Reinforcement Learning, Pan et al.,
- Towards Robust Legal Reasoning: Harnessing Logical LLMs in Law, Kant et al.,
- OctoTools: An Agentic Framework with Extensible Tools for Complex Reasoning, Lu et al.,
- R1-Searcher: Incentivizing the Search Capability in LLMs via Reinforcement Learning, Song et al.,
- RARE: Retrieval-Augmented Reasoning Modeling, Wang et al.,
- Graph-Augmented Reasoning: Evolving Step-by-Step Knowledge Graph Retrieval for LLM Reasoning, Wu et al.,
- Learning to Reason with Search for LLMs via Reinforcement Learning, Chen et al.,
- Fin-R1: A Large Language Model for Financial Reasoning through Reinforcement Learning, Liu et al.,
- m1: Unleash the Potential of Test-Time Scaling for Medical Reasoning with Large Language Models, Huang et al.,
Multilingual Long CoT
- Cross-lingual Prompting: Improving Zero-shot Chain-of-Thought Reasoning across Languages, Qin et al.,
- Not All Languages Are Created Equal in LLMs: Improving Multilingual Capability by Cross-Lingual-Thought Prompting, Huang et al.,
- xcot: Cross-lingual instruction tuning for cross-lingual chain-of-thought reasoning, Chai et al.,
- Multilingual large language model: A survey of resources, taxonomy and frontiers, Qin et al.,
- A Tree-of-Thoughts to Broaden Multi-step Reasoning across Languages, Ranaldi et al.,
- AutoCAP: Towards Automatic Cross-lingual Alignment Planning for Zero-shot Chain-of-Thought, Zhang et al.,
- Enhancing Advanced Visual Reasoning Ability of Large Language Models, Li et al.,
- DRT-o1: Optimized Deep Reasoning Translation via Long Chain-of-Thought, Wang et al.,
- A survey of multilingual large language models, Qin et al.,
- Demystifying Multilingual Chain-of-Thought in Process Reward Modeling, Wang et al.,
- The Multilingual Mind: A Survey of Multilingual Reasoning in Language Models, Ghosh et al.,
Multimodal Long CoT
- Large Language Models Can Self-Correct with Minimal Effort, Wu et al.,
- Multimodal Chain-of-Thought Reasoning in Language Models, Zhang et al.,
- Q*: Improving multi-step reasoning for llms with deliberative planning, Wang et al.,
- M3CoT: A Novel Benchmark for Multi-Domain Multi-step Multi-modal Chain-of-Thought, Chen et al.,
- A survey on evaluation of multimodal large language models, Huang et al.,
- Fine-Tuning Large Vision-Language Models as Decision-Making Agents via Reinforcement Learning, Zhai et al.,
- What factors affect multi-modal in-context learning? an in-depth exploration, Qin et al.,
- Enhancing Advanced Visual Reasoning Ability of Large Language Models, Li et al.,
- Insight-v: Exploring long-chain visual reasoning with multimodal large language models, Dong et al.,
- Llava-o1: Let vision language models reason step-by-step, Xu et al.,
- AtomThink: A Slow Thinking Framework for Multimodal Mathematical Reasoning, Xiang et al.,
- ARES: Alternating Reinforcement Learning and Supervised Fine-Tuning for Enhanced Multi-Modal Chain-of-Thought Reasoning Through Diverse AI Feedback, Byun et al.,
- Enhancing the reasoning ability of multimodal large language models via mixed preference optimization, Wang et al.,
- Slow Perception: Let's Perceive Geometric Figures Step-by-step, Wei et al.,
- Diving into Self-Evolving Training for Multimodal Reasoning, Liu et al.,
- Scaling inference-time search with vision value model for improved visual comprehension, Xiyao et al.,
- CoMT: A Novel Benchmark for Chain of Multi-modal Thought on Large Vision-Language Models, Cheng et al.,
- Inference Retrieval-Augmented Multi-Modal Chain-of-Thoughts Reasoning for Language Models, He et al.,
- Audio-CoT: Exploring Chain-of-Thought Reasoning in Large Audio Language Model, Ma et al.,
- BoostStep: Boosting mathematical capability of Large Language Models via improved single-step reasoning, Zhang et al.,
- InternLM-XComposer2.5-Reward: A Simple Yet Effective Multi-Modal Reward Model, Zang et al.,
- Can MLLMs Reason in Multimodality? EMMA: An Enhanced MultiModal ReAsoning Benchmark, Hao et al.,
- Visual Agents as Fast and Slow Thinkers, Sun et al.,
- Virgo: A Preliminary Exploration on Reproducing o1-like MLLM, Du et al.,
- Llamav-o1: Rethinking step-by-step visual reasoning in llms, Thawakar et al.,
- Inference-time scaling for diffusion models beyond scaling denoising steps, Ma et al.,
- Can We Generate Images with CoT? Let's Verify and Reinforce Image Generation Step by Step, Guo et al.,
- Imagine while Reasoning in Space: Multimodal Visualization-of-Thought, Li et al.,
- Monte Carlo Tree Diffusion for System 2 Planning, Yoon et al.,
- Boosting Multimodal Reasoning with MCTS-Automated Structured Thinking, Wu et al.,
- Audio-Reasoner: Improving Reasoning Capability in Large Audio Language Models, Xie et al.,
- Visual-RFT: Visual Reinforcement Fine-Tuning, Liu et al.,
- Qwen2. 5-Omni Technical Report, Xu et al.,
- Vision-r1: Incentivizing reasoning capability in multimodal large language models, Huang et al.,
- Lmm-r1: Empowering 3b lmms with strong reasoning abilities through two-stage rule-based rl, Peng et al.,
- Reason-RFT: Reinforcement Fine-Tuning for Visual Reasoning, Tan et al.,
- OThink-MR1: Stimulating multimodal generalized reasoning capabilities through dynamic reinforcement learning, Liu et al.,
- Grounded Chain-of-Thought for Multimodal Large Language Models, Wu et al.,
- Test-Time View Selection for Multi-Modal Decision Making, Jain et al.,
- Rethinking RL Scaling for Vision Language Models: A Transparent, From-Scratch Framework and Comprehensive Evaluation Scheme, Ma et al.,
Safety and Stability for Long CoT
- Larger and more instructable language models become less reliable, Zhou et al.,
- On the Hardness of Faithful Chain-of-Thought Reasoning in Large Language Models, Tanneru et al.,
- The Impact of Reasoning Step Length on Large Language Models, Jin et al.,
- Unlocking the Capabilities of Thought: A Reasoning Boundary Framework to Quantify and Optimize Chain-of-Thought, Chen et al.,
- Can Large Language Models Understand You Better? An MBTI Personality Detection Dataset Aligned with Population Traits, Li et al.,
- o3-mini vs DeepSeek-R1: Which One is Safer?, Arrieta et al.,
- Efficient Reasoning with Hidden Thinking, Shen et al.,
- Think More, Hallucinate Less: Mitigating Hallucinations via Dual Process of Fast and Slow Thinking, Cheng et al.,
- Explicit vs. Implicit: Investigating Social Bias in Large Language Models through Self-Reflection, Zhao et al.,
- Challenges in Ensuring AI Safety in DeepSeek-R1 Models: The Shortcomings of Reinforcement Learning Strategies, Parmar et al.,
- Early External Safety Testing of OpenAI's o3-mini: Insights from the Pre-Deployment Evaluation, Arrieta et al.,
- International AI Safety Report, Bengio et al.,
- GuardReasoner: Towards Reasoning-based LLM Safeguards, Liu et al.,
- OVERTHINKING: Slowdown Attacks on Reasoning LLMs, Kumar et al.,
- A Mousetrap: Fooling Large Reasoning Models for Jailbreak with Chain of Iterative Chaos, Yao et al.,
- MetaSC: Test-Time Safety Specification Optimization for Language Models, Gallego et al.,
- Leveraging Reasoning with Guidelines to Elicit and Utilize Knowledge for Enhancing Safety Alignment, Wang et al.,
- The Hidden Risks of Large Reasoning Models: A Safety Assessment of R1, Zhou et al.,
- Reasoning and the Trusting Behavior of DeepSeek and GPT: An Experiment Revealing Hidden Fault Lines in Large Language Models, Lu et al.,
- Superintelligent Agents Pose Catastrophic Risks: Can Scientist AI Offer a Safer Path?, Bengio et al.,
- Emergent Response Planning in LLM, Dong et al.,
- Investigating the Impact of Quantization Methods on the Safety and Reliability of Large Language Models, Kharinaev et al.,
- Safety Evaluation of DeepSeek Models in Chinese Contexts, Zhang et al.,
- Reasoning Does Not Necessarily Improve Role-Playing Ability, Feng et al.,
- H-CoT: Hijacking the Chain-of-Thought Safety Reasoning Mechanism to Jailbreak Large Reasoning Models, Including OpenAI o1/o3, DeepSeek-R1, and Gemini 2.0 Flash Thinking, Kuo et al.,
- BoT: Breaking Long Thought Processes of o1-like Large Language Models through Backdoor Attack, Zhu et al.,
- " Nuclear Deployed!": Analyzing Catastrophic Risks in Decision-making of Autonomous LLM Agents, Xu et al.,
- SafeChain: Safety of Language Models with Long Chain-of-Thought Reasoning Capabilities, Jiang et al.,
- Reasoning-to-Defend: Safety-Aware Reasoning Can Defend Large Language Models from Jailbreaking, Zhu et al.,
- CER: Confidence Enhanced Reasoning in LLMs, Razghandi et al.,
- Measuring Faithfulness of Chains of Thought by Unlearning Reasoning Steps, Tutek et al.,
- The Hidden Dimensions of LLM Alignment: A Multi-Dimensional Safety Analysis, Pan et al.,
- Policy Frameworks for Transparent Chain-of-Thought Reasoning in Large Language Models, Chen et al.,
- Do Chains-of-Thoughts of Large Language Models Suffer from Hallucinations, Cognitive Biases, or Phobias in Bayesian Reasoning?, Araya et al.,
- Process or Result? Manipulated Ending Tokens Can Mislead Reasoning LLMs to Ignore the Correct Reasoning Steps, Cui et al.,
- Safety Tax: Safety Alignment Makes Your Large Reasoning Models Less Reasonable, Huang et al.,
- Recitation over Reasoning: How Cutting-Edge Language Models Can Fail on Elementary School-Level Reasoning Problems?, Yan et al.,
- Reasoning Models Don’t Always Say What They Think, Chen et al.,
Resources
Open-Sourced Training Framework
- OpenRLHF: An Easy-to-use, Scalable and High-performance RLHF Framework, Hu et al.,
- LLM Reasoners: New Evaluation, Library, and Analysis of Step-by-Step Reasoning with Large Language Models, Hao et al.,
- OpenR: An Open Source Framework for Advanced Reasoning with Large Language Models, Wang et al.,
- TinyZero, Pan et al.,
- R1-V: Reinforcing Super Generalization Ability in Vision-Language Models with Less Than 3, Chen et al.,
- VL-Thinking: An R1-Derived Visual Instruction Tuning Dataset for Thinkable LVLMs, Chen et al.,
- VLM-R1: A stable and generalizable R1-style Large Vision-Language Model, Shen et al.,
- 7B Model and 8K Examples: Emerging Reasoning with Reinforcement Learning is Both Effective and Efficient, Zeng et al.,
- Open R1, Team et al.,
- DeepScaleR: Surpassing O1-Preview with a 1.5B Model by Scaling RL, Luo et al.,
- X-R1, Team et al.,
- Open-Reasoner-Zero: An Open Source Approach to Scaling Reinforcement Learning on the Base Model, Jingcheng Hu and Yinmin Zhang and Qi Han and Daxin Jiang and Xiangyu Zhang et al.,
- Logic-RL: Unleashing LLM Reasoning with Rule-Based Reinforcement Learning, Xie et al.,
- R1-Multimodal-Journey, Shao et al.,
- Open-R1-Multimodal, Lab et al.,
- Video-R1, Team et al.,
- Dapo: An open-source llm reinforcement learning system at scale, Yu et al.,
- VAPO: Efficient and Reliable Reinforcement Learning for Advanced Reasoning Tasks, YuYue et al.,